
Data Passing with Volumes¶
This guide will walk you through understanding how Kale uses snapshots and volumes for data passing.
What You’ll Need¶
- An EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how Kale SDK works.
Procedure¶
Create a new Notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or EKF release.Connect to the server, open a terminal, and install
scikit-learn:$ pip3 install --user scikit-learn==0.23.0Create a new python file and name it
kale_data_passing.py:$ touch kale_data_passing.pyCopy and paste the following code inside
kale_data_passing.py:sdk.py
1 # Copyright © 2021-2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script trains an ML pipeline to solve a binary classification task. 6 """ 7 8 from kale.sdk import pipeline, step 9 from sklearn.datasets import make_classification 10 from sklearn.linear_model import LogisticRegression 11 from sklearn.model_selection import train_test_split 12 13 14 @step(name="data_loading") 15 def load(random_state): 16 """Create a random dataset for binary classification.""" 17 rs = int(random_state) 18 x, y = make_classification(random_state=rs) 19 return x, y 20 21 22 @step(name="data_split") 23 def split(x, y): 24 """Split the data into train and test sets.""" 25 x, x_test, y, y_test = train_test_split(x, y, test_size=0.1) 26 return x, x_test, y, y_test 27 28 29 @step(name="model_training") 30 def train(x, x_test, y, training_iterations): 31 """Train a Logistic Regression model.""" 32 iters = int(training_iterations) 33 model = LogisticRegression(max_iter=iters) 34 model.fit(x, y) 35 print(model.predict(x_test)) 36 37 38 @pipeline(name="binary-classification", experiment="kale-tutorial") 39 def ml_pipeline(rs=42, iters=100): 40 """Run the ML pipeline.""" 41 x, y = load(rs) 42 x, x_test, y, y_test = split(x=x, y=y) 43 train(x, x_test, y, training_iterations=iters) 44 45 46 if __name__ == "__main__": 47 ml_pipeline(rs=42, iters=100) In this code sample, you start with a standard Python script that trains a Logistic Regression model. Moreover, you have decorated the functions using the Kale SDK. To read more about how to create this file, head to the corresponding Kale SDK user guide.
Compile and run the pipeline, note that Kale takes a snapshot of the Notebook’s volumes:
$ python3 -m kale kale_parameters.py --kfp [...] 2021-09-21 09:07:50 Kale rokutils:281 [INFO] Creating Rok bucket 'notebooks'... 2021-09-21 09:07:50 Kale rokutils:291 [INFO] Rok bucket 'notebooks' already exists 2021-09-21 09:07:51 Kale rokutils:157 [INFO] Monitoring Rok snapshot with task id: 1556b315b8b54aeaa6a5a241cf75e42a Rok Task: |********************************| 100/100 [...]Navigate to the KFP UI to the run page. Note that the new pipeline includes a step called
create-volume-1. This step is responsible for provisioning a clone of the Notebook’s workspace volume. If the Notebook had also some data volumes, we would see more pipeline steps calledcreate-volume-*, each one provisioning a clone of a data volume.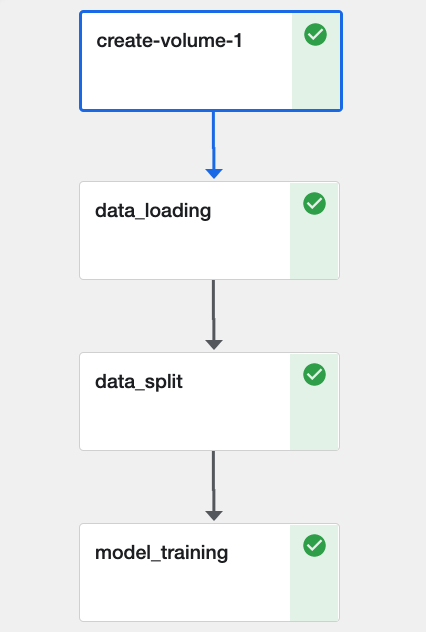
Volumes and Snapshots¶
When you create your Notebook Server using the Jupyter Web App, by default a new PVC is mounted under the user’s home directory. We call this volume, workspace volume. Moreover, you can decide to provision more volumes to be mounted at locations of your choice. We call these volumes, data volumes.
Whenever you submit a pipeline to KFP, Kale clones the Notebook’s volumes for two important reasons:
Marshalling: a mechanism to seamlessly pass data between steps. This system requires a shared folder where Kale can serialize and de-serialize data.
Kale uses a hidden folder within the workspace volume as the shared marshalling location.
Reproducibility, experimentation: when you are working on a Notebook, it is often the case that you install new libraries, write new modules, create or download assets required by your code. By seamlessly cloning the workspace and data volumes, all your environment is versioned and replicated to the new pipeline. Thus, the pipeline is always reproducible, thanks to the immutable snapshots, and you do not have to build new Docker images for each pipeline run.
Important
Currently Kale requires to take a snapshot of the Notebook volumes, because every step needs to be sourced from its original Python module or Notebook. In the near future we will provide an option to compile and run pipelines without needing to take volume snapshots, and at the same time ensure the immutability and reproducibility of the pipeline steps.
Marshal Volume¶
Using the workspace volume to marshal data can become problematic in case your
pipeline steps need to pass large assets between them. Imagine if the load
step of the pipeline above produced a dataset too large for the workspace
volume to contain it. You can ask Kale to provision a volume dedicated to data
passing, deciding its size and mount location:
| 1 | # Copyright © 2021-2022 Arrikto Inc. All Rights Reserved. | |
| 2 | ||
| 3 | """Kale SDK. | |
| 4-34 | ||
| 4 | ||
| 5 | This script trains an ML pipeline to solve a binary classification task. | |
| 6 | """ | |
| 7 | ||
| 8 | from kale.sdk import pipeline, step | |
| 9 | from sklearn.datasets import make_classification | |
| 10 | from sklearn.linear_model import LogisticRegression | |
| 11 | from sklearn.model_selection import train_test_split | |
| 12 | ||
| 13 | ||
| 14 | @step(name="data_loading") | |
| 15 | def load(random_state): | |
| 16 | """Create a random dataset for binary classification.""" | |
| 17 | rs = int(random_state) | |
| 18 | x, y = make_classification(random_state=rs) | |
| 19 | return x, y | |
| 20 | ||
| 21 | ||
| 22 | @step(name="data_split") | |
| 23 | def split(x, y): | |
| 24 | """Split the data into train and test sets.""" | |
| 25 | x, x_test, y, y_test = train_test_split(x, y, test_size=0.1) | |
| 26 | return x, x_test, y, y_test | |
| 27 | ||
| 28 | ||
| 29 | @step(name="model_training") | |
| 30 | def train(x, x_test, y, training_iterations): | |
| 31 | """Train a Logistic Regression model.""" | |
| 32 | iters = int(training_iterations) | |
| 33 | model = LogisticRegression(max_iter=iters) | |
| 34 | model.fit(x, y) | |
| 35 | print(model.predict(x_test)) | |
| 36 | ||
| 37 | ||
| 38 | - | @pipeline(name="binary-classification", experiment="kale-tutorial") |
| 39 | + | @pipeline(name="binary-classification", experiment="kale-tutorial", |
| 40 | + | marshal_volume=True, marshal_volume_size="10Gi", |
| 41 | + | marshal_path="/data/marshal") |
| 42 | def ml_pipeline(rs=42, iters=100): | |
| 43 | """Run the ML pipeline.""" | |
| 44 | x, y = load(rs) | |
| 45-47 | ||
| 45 | x, x_test, y, y_test = split(x=x, y=y) | |
| 46 | train(x, x_test, y, training_iterations=iters) | |
| 47 | ||
| 48 | ||
| 49 | if __name__ == "__main__": | |
| 50 | ml_pipeline(rs=42, iters=100) |
When you activate the marshal volume, Kale uses it to marshal data between steps, but still keeps the Notebook’s clones, for the reasons explained above:
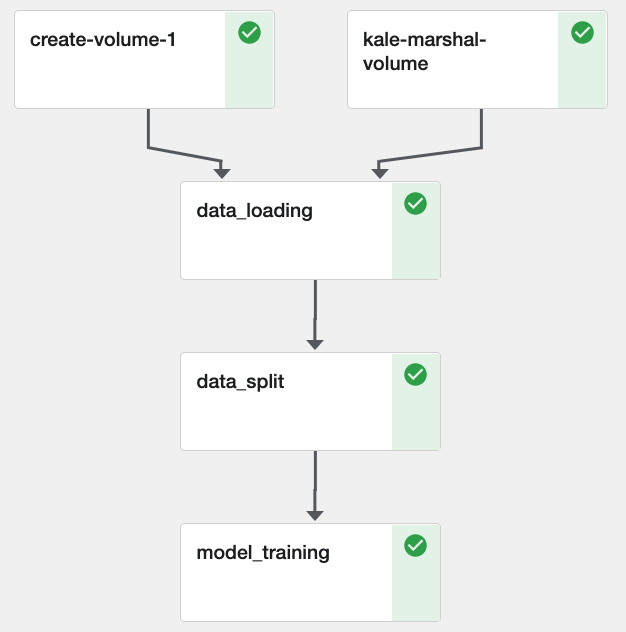
Note
You can also use the marshal volume to perform data passing yourself, in case you need to write files to a shared location and have downstream steps consume them.
Summary¶
You have learned how Kale uses volumes and snapshots to perform data passing and how to create a marshal volume.
What’s Next¶
The next step is to learn how to use type-hints for the step parameters of your pipelines.