
Kale Notebook Cell Types¶
To create a Kubeflow Pipeline (KFP) from a Jupyter Notebook using Kale, annotate the cells of your notebook selecting from six Kale cell types. Some of the cell types require a small number of parameters.
Kale uses the annotations you supply to define a Kubeflow pipeline. Each step of the pipeline will run in its own container in a Kubernetes deployment. The annotations you apply to cells in your notebook enable Kale to manage dependencies for each step and marshal data correctly as inputs and outputs for each step of a pipeline. See below for the list of cell types and a brief summary of each.
| Cell type | Cell should contain |
|---|---|
| Imports | Blocks of code that import other modules your machine learning pipeline requires and may be needed by more than one step. |
| Functions | Functions used later in your machine learning pipeline; global variable definitions (other than pipeline parameters); and code that initializes lists, dictionaries, objects, and other values used throughout your pipeline. |
| Pipeline Parameters | Definitions for global variables used to parameterize your machine learning workflow. These are often training hyperparameters. |
| Pipeline Metrics | Lines of code that log or print values used to measure the success of your model. |
| Pipeline Step | Code that implements the core logic of a discrete step in your workflow. |
| Skip Cell | Any code that you want Kale to ignore. |
Imports Cells¶
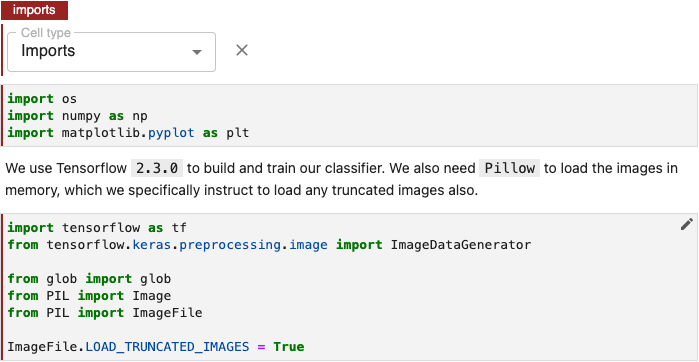
Annotate notebook cells with the label Imports to identify blocks of code that import other modules your machine learning pipeline requires.
Purpose¶
Imports cells help Kale identify all dependencies for pipeline steps. Kale prepends the code in Imports cells to the code specific to a pipeline step in the execution environment it creates for that step. See How Kale Creates a Pipeline Step for more detail.
Annotate Imports Cells¶
To annotate imports, edit the first cell containing import statements by clicking the pencil icon in the upper right corner and select Cell type > Imports.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
Functions Cells¶
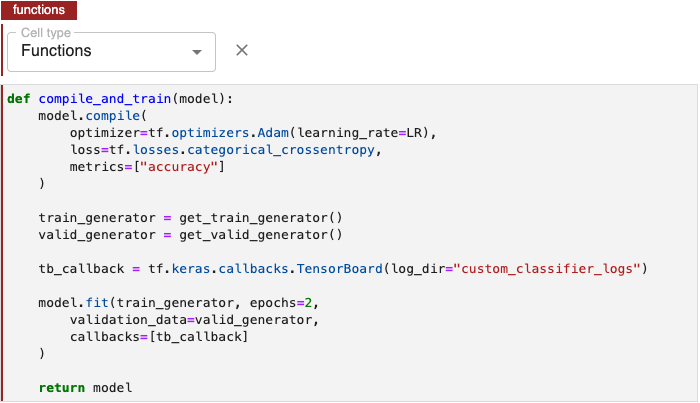
Annotate notebook cells with the label Functions to identify blocks of code containing:
- Functions used later in your machine learning pipeline.
- Global variable definitions (other than pipeline parameters) and code that initializes lists, dictionaries, objects, and other values used throughout your pipeline.
Note
Though pipeline parameters are often written as global variables, you should annotate pipeline parameters using the Pipeline Parameters label. This will enable Kale to configure the Kubeflow pipeline it defines with the appropriate input parameters.
Purpose¶
Functions cells help Kale identify all dependencies for pipeline steps. Kale creates pipeline steps by prepending Imports cells followed by Functions cells to the code specific to a pipeline step in the execution environment it creates for that step. See How Kale Creates a Pipeline Step for more detail.
Annotate Functions Cells¶
To identify functions, global variable declarations, and initialization code, edit the first cell in a block containing this code by clicking the pencil icon in the upper right corner and select Cell type > Functions.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
Pipeline Parameters Cells¶
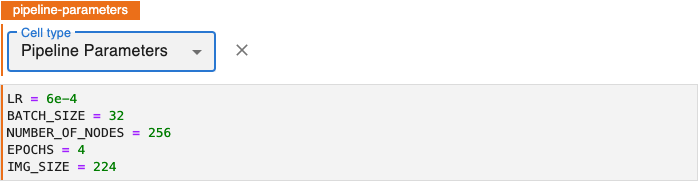
Annotate notebook cells as Pipeline Parameters to identify blocks of code that define variables to be used as hyperparameters. These should be values that you might experiment with as you evaluate the relative performance of a pipeline run with different hyperparameter values.
Hyperparameters¶
Hyperparameters are variables that control a model training process. They include:
- The learning rate.
- The number of layers in a neural network.
- The number of nodes in each layer.
Hyperparameter values are not learned. In contrast to the node weights and other training parameters, a model training process does not adjust hyperparameter values.
See Hyperparameter Tuning for more detail on hyperparamaters metrics and other key concepts.
Purpose¶
Kale uses the values in Pipeline Parameters cells to define Kubeflow Pipeline
(KFP) PipelineParam objects and initializes the KF Pipeline with these
parameters. KFP includes pipeline parameters values in the artifacts it creates
for pipeline runs to facilitate review of results from experiments comparing
multiple runs of a pipeline.
Annotate Pipeline Parameters Cells¶
To annotate pipeline parameters, edit the first cell containing pipeline parameters by clicking the pencil icon in the upper right corner and select Cell type > Pipeline Parameters.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
Pipeline Step Cells¶
Annotate notebook cells with the label Pipeline Step to identify code that implements one of the main components or tasks of a machine learning workflow. A pipeline step typically represents a milestone in data preparation, training, evaluation, tuning, prediction or other phases of a workflow.
Kale creates pipeline steps by prepending Imports cells followed by Functions cells to cells annotated for a particular Pipeline Step. These cells together comprise the code Kale uses in the execution environment it creates for a pipeline step. See How Kale Creates a Pipeline Step for more detail.
Annotate Pipeline Step Cells¶
To identify code that implements a step in a machine learning workflow:
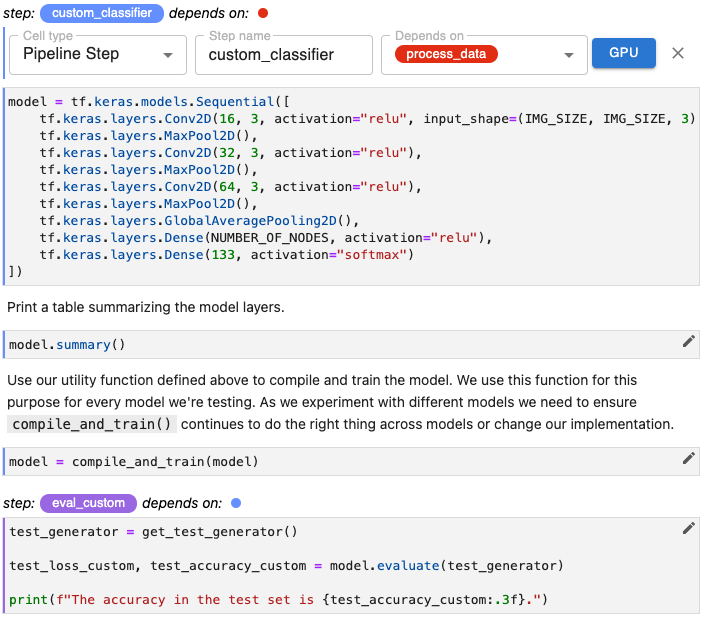
Edit the first cell containing this code by clicking the pencil icon in the upper right corner and select Cell type > Pipeline Step.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
Specify a unique step name.
(Optional) Select one or more steps that the step depends on.
(Optional) Specify that this step should run on a GPU node.
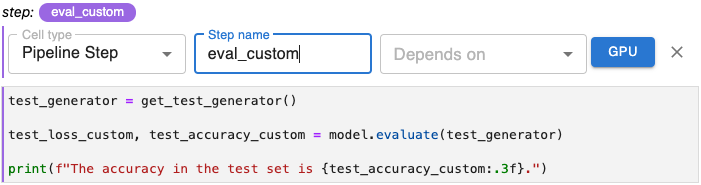
Step name Parameter¶
Step name is the label by which you reference a step in a pipeline. As the step name, create a label that is unique and descriptive. You will use this name as a reference as you define dependency relationships between steps in your pipeline.
Note
The step name must consist of only lowercase alphanumeric characters or ‘_’. The first character must be a lowercase letter.
Depends on Parameter¶
The values you select for Depends on list the other steps that must execute before the step you are annotating.
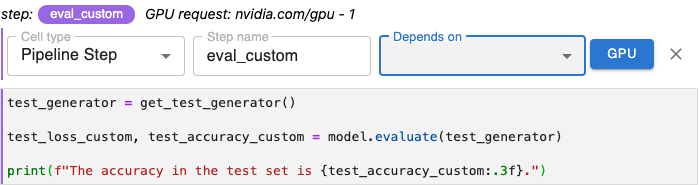
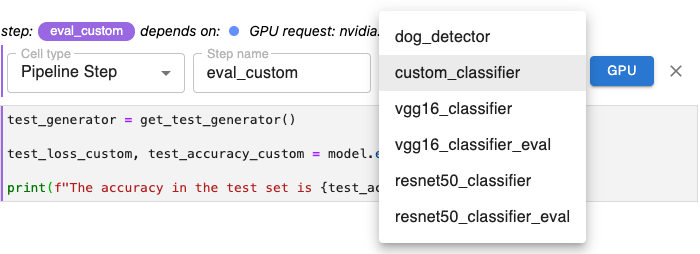
To add dependencies, use the Depends on pull-down menu to select each step whose output will serve as input for the step you are annotating.
In the example below, since the step eval_custom evaluates the model created in the step custom_classifier, we select that step from the Depends on pull-down menu.
When selecting steps using the Depends on pull-down menu, identify only steps that are immediate dependencies. Do not include all dependencies back through the machine learning pipeline.
Together, the dependencies for all steps in a pipeline, define the execution graph for that pipeline. This helps Kale determine, for example, whether there are branches of your pipeline that can run in parallel.
Specify Multiple Dependencies: A given step may depend on the outputs from more than one other step. The Depends on pull-down menu enables you to select as many other steps as necessary. Select each dependency one at a time.
Remove Dependencies: To remove a dependency already selected, select the name of that step again from the Depends on pull-down menu. The items in this menu function as toggles for specifying other steps as dependencies.
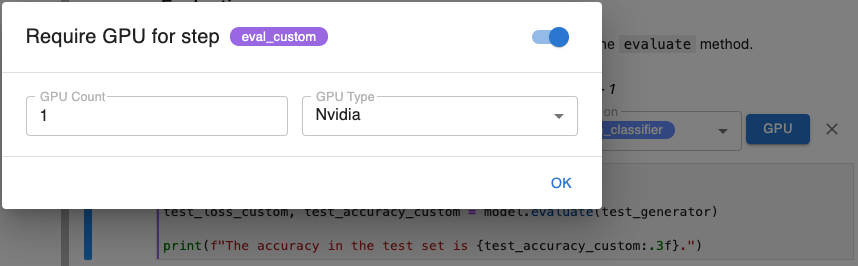
GPU Parameter¶
Click the GPU button when annotating a step, to require that step to run on a GPU. In the modal that appears, enable this requirement using the toggle and specify a number of GPUs and the type of GPU requested.
DeployConfig Parameter¶
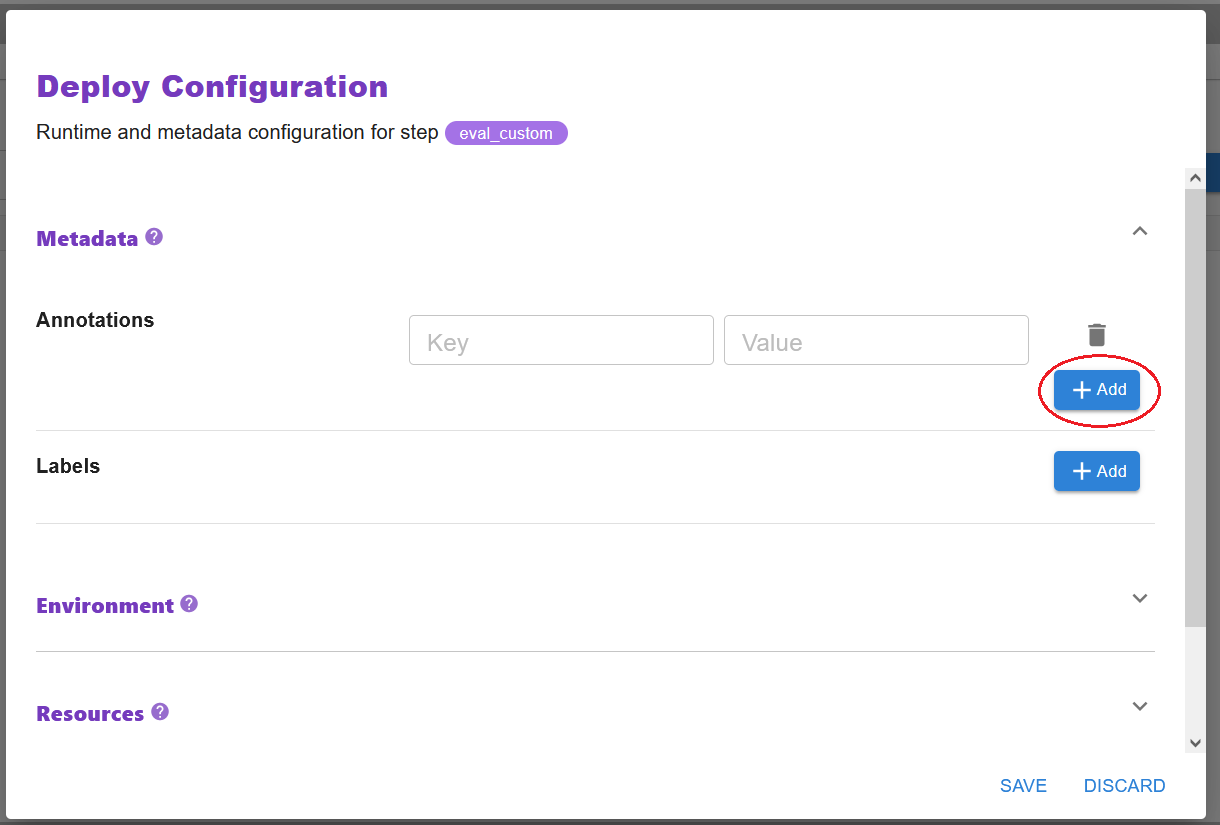
Click the DeployConfig button when annotating a step, to set configurations on the step, regarding its deployment on Kubernetes. For example, you can specify environment variables, configure resource requests, set labels, or even tinker with the scheduling decision.

Add configuration: Navigate to the configuration type you want to add and expand the menu of that group. For each section you want to add a configuration for, click the + Add button and fill in the form.
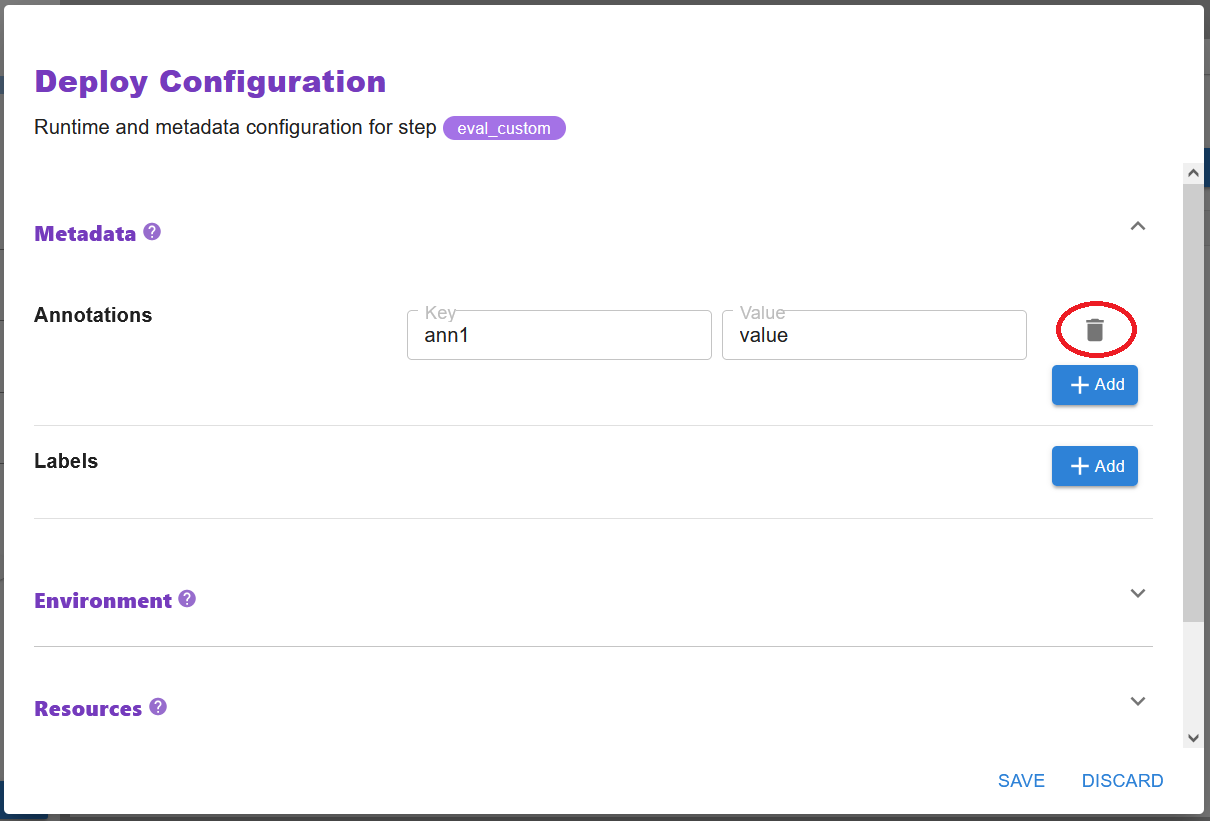
Delete configuration: Navigate to the configuration you want to unset and click on the trashcan button.
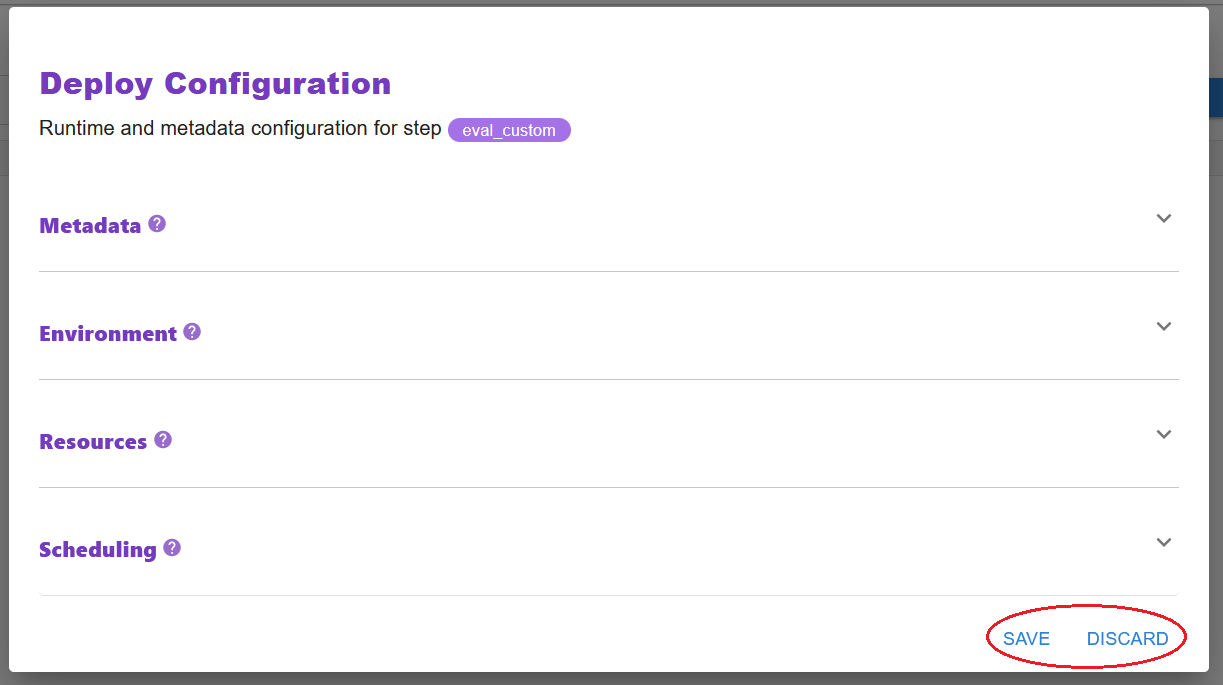
Edit configuration: Navigate to the configuration you want to edit, edit the fields in the form, and click on the SAVE button to store them.
Note
Once you are done with the configurations, click the SAVE button to store them or the DISCARD button to discard your changes.
See also
Behind the scenes of this parameter is the DeployConfig API. Check out the DeployConfig API documentation for more details on each available configuration:
Parallel Pipeline Steps¶
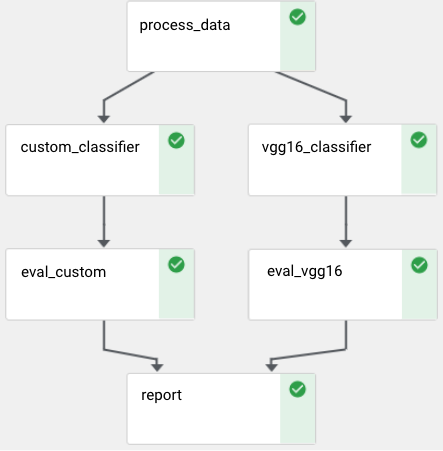
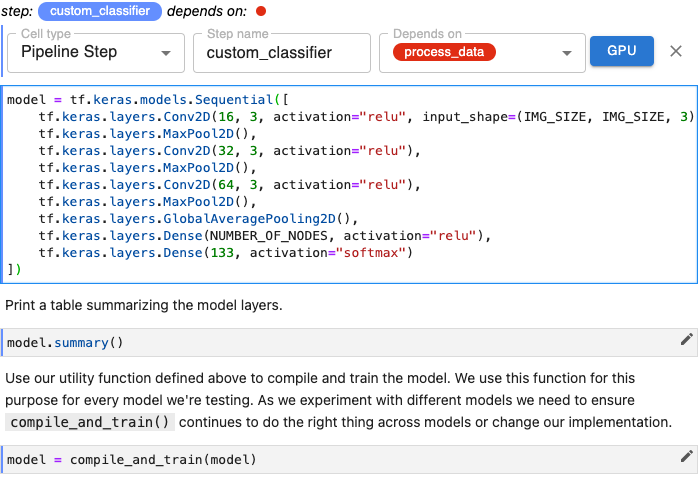
Pipeline steps that are independent of one another can run in parallel. For example, the two steps represented below each depend on a step named process_data, but are otherwise independent. Kale uses the dependency graph reflected in the way you define pipeline steps to orchestrate pipeline runs, taking advantage of your Kubernetes infrastructure to run a pipeline as efficiently as possible.
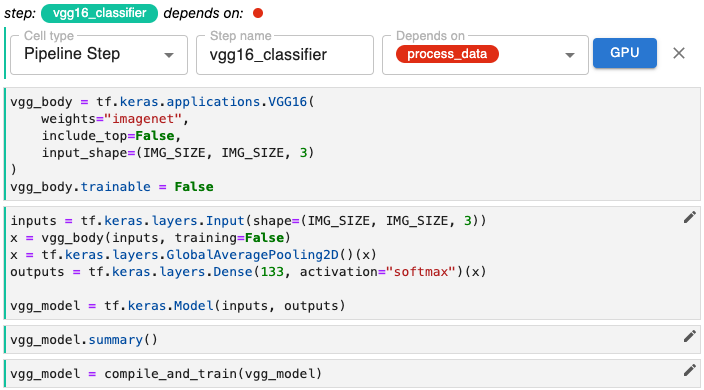
The step vgg16_classifier can run in parallel with the step custom_classifier.
Skip Cells¶
Use Skip to annotate notebook cells that you want Kale to ignore as it defines a Kubeflow pipeline.
Purpose¶
Common uses of the Skip annotation include identifying console logging and other diagnostic code useful in developing a step of pipeline, but which is not part of your machine learning workflow.
You might also choose to skip cells associated with models you want to eliminate from your pipeline during, e.g., hyperparamter tuning.
Annotate Skip Cells¶
To annotate skip cells, edit the first cell containing code you want Kale to ignore by clicking the pencil icon in the upper right corner and select Cell type > Skip Cell.

Pipeline Metrics Cells¶
Annotate a notebook cell with the label Pipeline Metrics to identify code that outputs the results you want to evaluate for a pipeline run. Kale enables you to perform hyperparameter tuning using Katib in order to optimize a model based on a selected pipeline metric. In order to perform Katib experiments, organize all pipeline metrics into a single cell and annotate the cell using the Pipeline Metrics.
Purpose¶
Based on the variables referenced in a Pipeline Metrics cell, Kale will define pipeline metrics that the Kubeflow Pipelines (KFP) system will produce for every pipeline run. In addition, Kale will associate each one of these metrics to the steps that produced them.
Pipeline metrics are key to the AutoML capabilities of Kubeflow and Kale. You will need to choose a single pipeline metric as the search objective metric for hyperparameter tuning experiments. Tracking pipeline metrics is essential to evaluating performance across multiple runs of a pipeline that have been parameterized differently or modified while still in the experimental phase of developing a model.
Annotate Pipeline Metrics Cell¶
Note
Pipeline metrics should be considered the result of pipeline execution, not the result of an individual step. You should only annotate one cell with Pipeline Metrics and that cell should be the last cell in your notebook.
To identify pipeline metrics, edit the cell containing pipeline metrics statements by clicking the pencil icon in the upper right corner and select Cell type > Pipeline Metrics.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
