
Rok Snapshotting¶
This section will discuss the Rok cluster setup, how and when Rok takes snapshots, and how to restore snapshots.
Kale Kubeflow Pipeline and Rok Snapshots¶
Rok is present on every node in a MiniKF or Arrikto Enterprise Kubeflow cluster. Rok’s presence enables you to create snapshots of local PersistentVolumes to capture point in time representation of volume storage. Rok is deployed via its own Rok Operator, which runs as a StatefulSet, and which creates a number of resources: the most important is a Rok DaemonSet, a Rok CSI DaemonSet, which run on all nodes, and a Rok CSI Controller StatefulSet. The user just applies the Operator YAML and creates a new RokCluster resource. The Rok Operator communicates and synchronizes the Rok Pods across the cluster.

Kale generates Kubeflow pipelines from tagged cells in the JupyterLab notebook, which has a workspace volume and zero or more data volumes. Arrikto does recommend defining at least one data volume during notebook server creation. When you create a Kubeflow Pipeline run using Kale, Rok will snapshot all notebook volumes and then clone them for the pipeline steps to use them. By seamlessly cloning the workspace and data volumes, your environment is versioned and replicated to the new pipeline, which is then executed.
Kubeflow Pipeline and Initial Rok Snapshot¶
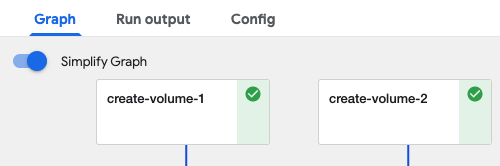
In the Kubeflow Pipelines run you will see a step called create-volume-1.
This is the step responsible for provisioning a clone of the notebook workspace
volume. If there are data volumes attached to the notebook then you will see one
step per data volume labelled as create-volume-#. You can select the
pipeline run from the Kubeflow Pipelines UI to see the volume creation steps.
There are two important reasons for this cloning process.
Marshaling: a mechanism to seamlessly pass data between steps. Kale uses a hidden folder within the workspace volume as the shared marshaling location to serialize and deserialize data.
See also
Reproducibility, experimentation: when working on a notebook, it is often the case that you install new libraries, write new modules, create or download assets required by your code. By seamlessly cloning the workspace and data volumes, all your environment is versioned and replicated to the new pipeline.
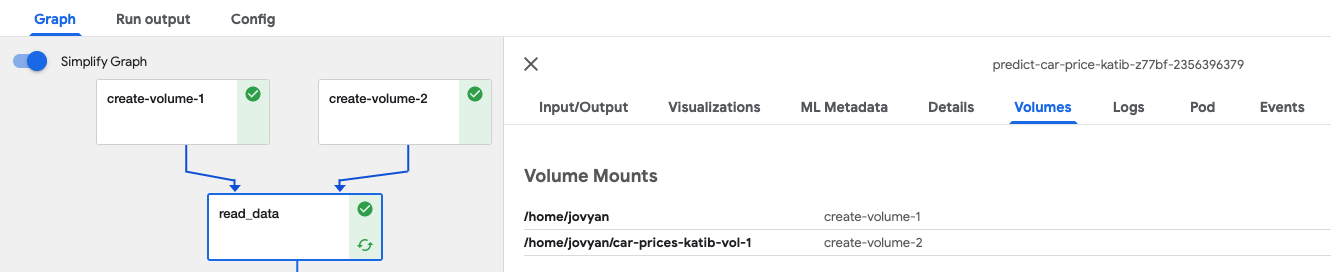
The newly cloned volumes are mounted by the rok-csi driver to the Pods in
which the pipeline steps run. You can select the pipeline step cell and select
Volumes to see where the dependent volumes are mounted. The Arrikto
provided Docker images default to using the /home/ jovyan/* directories.
Kubeflow Pipeline Steps and Rok Snapshots¶
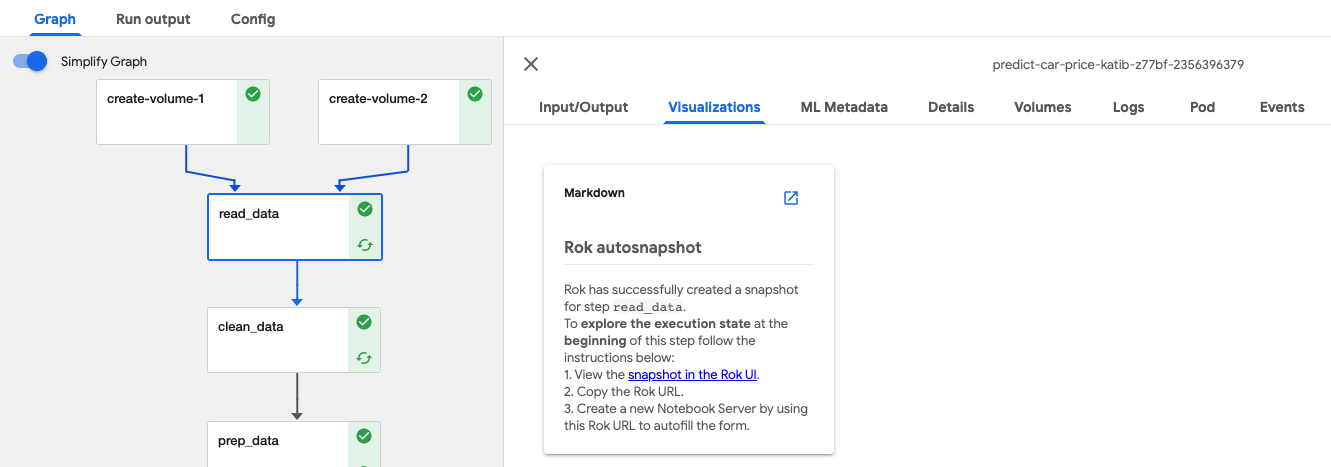
Rok takes snapshots just before and just after execution of individual pipeline steps. This functionality allows you to restore not just an environment but the execution state of a Kubeflow pipeline initiated by Kale from within a JupyterLab notebook. You can select Visualizations on an individual step to see the snapshot details.
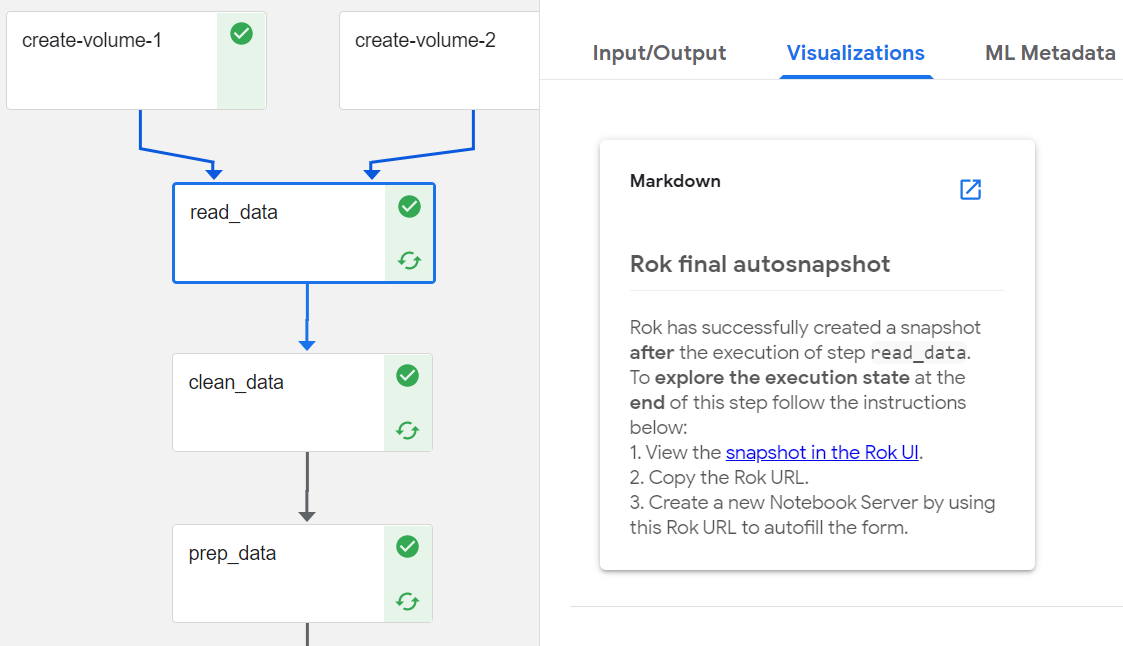
Scroll down to view he snapshot taken after the step completes, which will
be tagged with final:
Rok Snapshot Creation and Rok Buckets¶
To create a snapshot, Rok hashes, de-duplicates, and versions snapshots and then stores the de-duplicated, content-addressable parts on an Object Storage service (e.g., Amazon S3) that is close to the specific Kubernetes cluster. Rok creates buckets of snapshots, which are associated with a specific KFP experiment, which is a set of Kubeflow Pipelines runs.
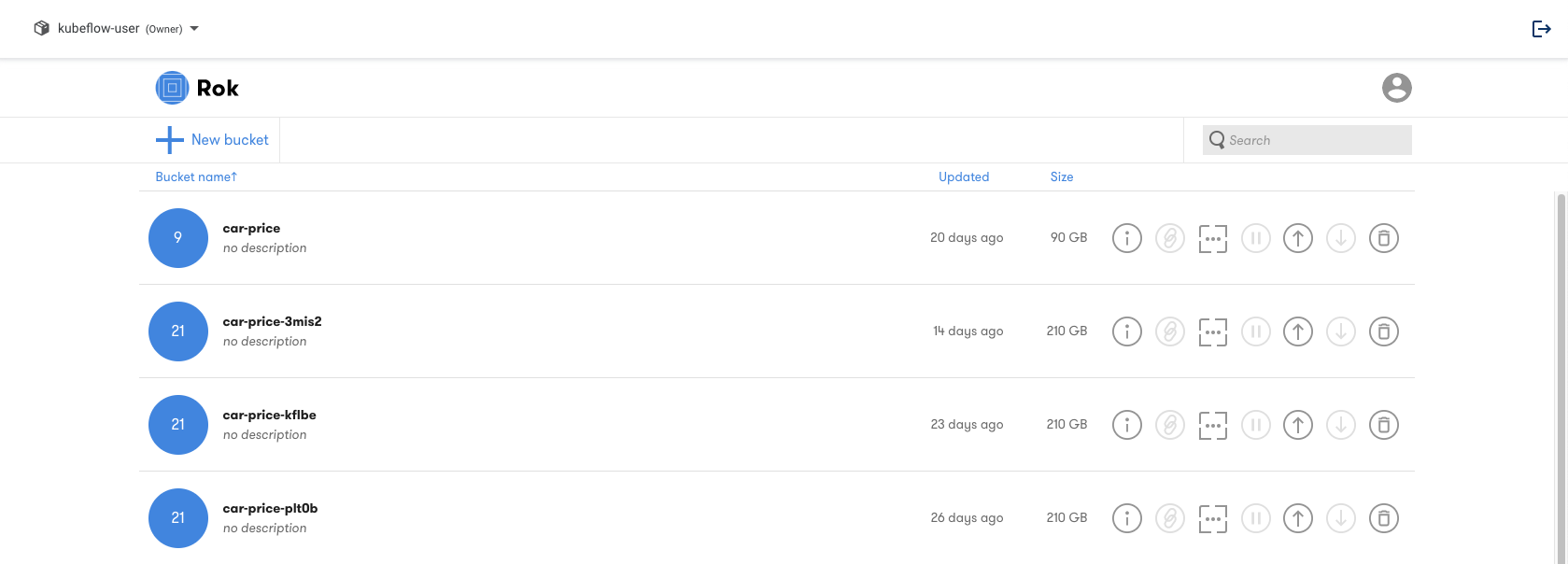
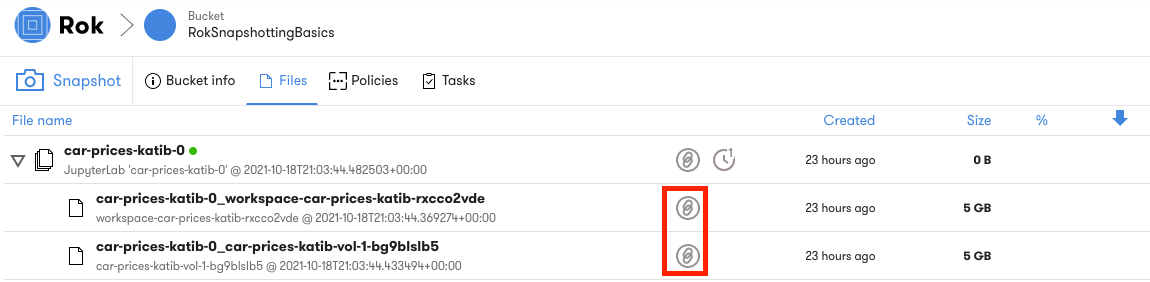
Expanding a bucket will show the list of snapshots that have been taken during Kubeflow pipeline execution. Each Kubeflow Pipelines run is associated with a file inside a Rok bucket. These associations can be identified through the Rok UI.
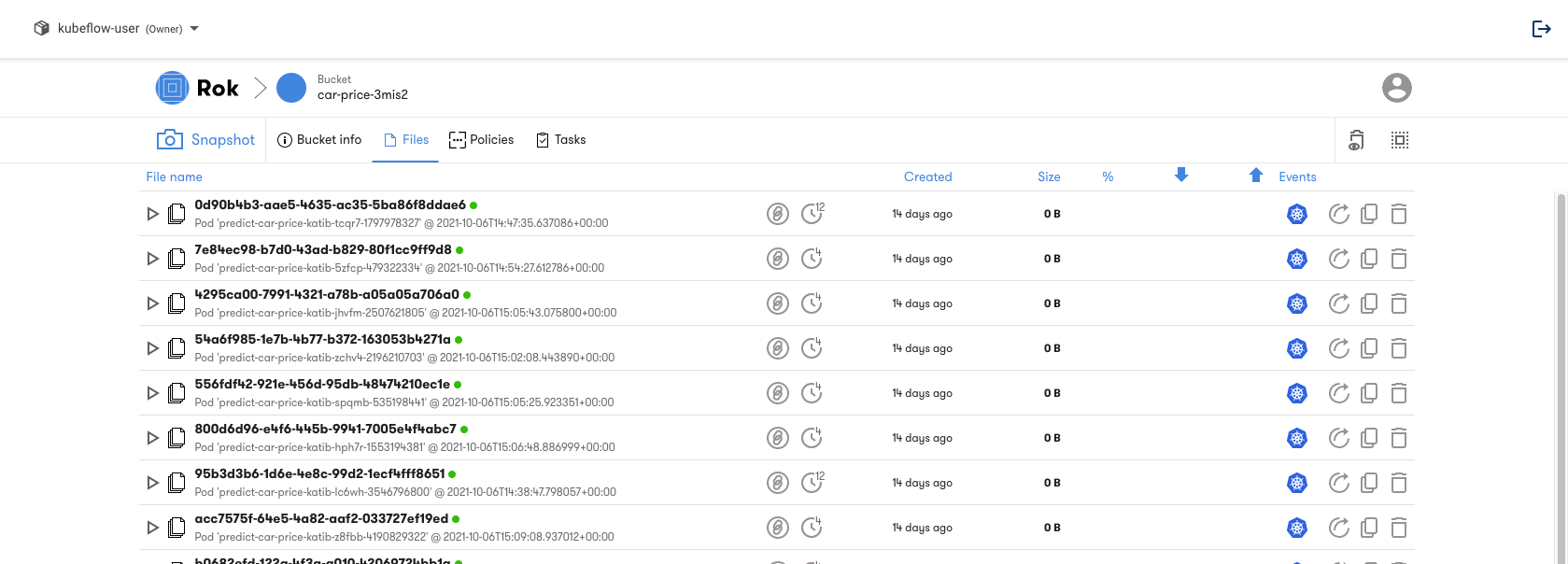
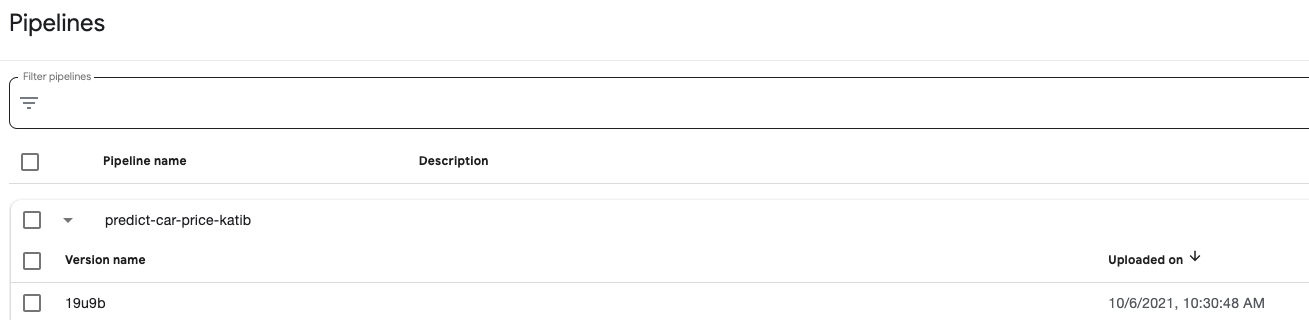
The bucket name suffix will be reflected in the name of the pipeline runs and
the name of the KFP experiment. Notice that in the image below the Rok bucket
name contains the reference text 3mis2:
Navigating over to the Runs page you can now relate the Rok
bucket and snapshots with the associated pipeline runs. Notice in the image
below each run contains the reference text 3mis2:
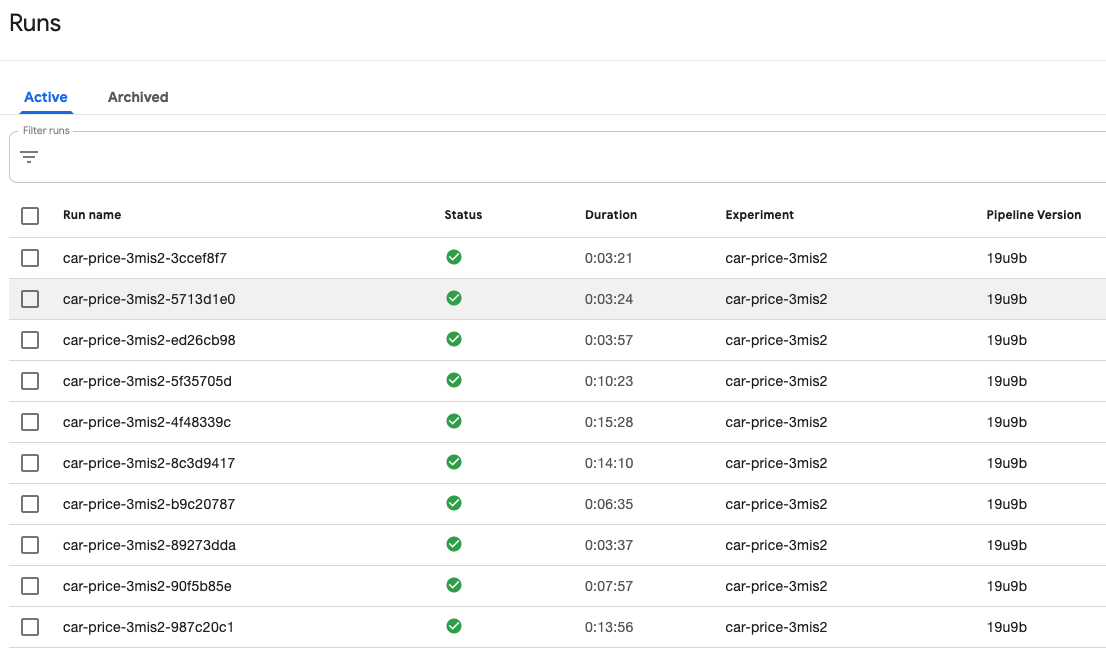
The runs are tagged with a pipeline version so they can be associated with a
Kubeflow pipeline definition. In the image above the pipeline version is
19u9b, which can be found in the Pipelines page.
Rok Snapshots Outside of I/O Path¶
Snapshots are taken at the start of execution and before and after each step. However taking snapshots does not impact application performance. Snapshotting happens outside the application I/O path using Arrikto’s Linux kernel enhancements contained in the Arrikto provided Docker images. These enhancements are loaded as modules into the kernel during the creation of the Rok cluster. As a result, snapshotting will not impact performance of applications in the Pods.

Rok Snapshots & Environment Restoration¶
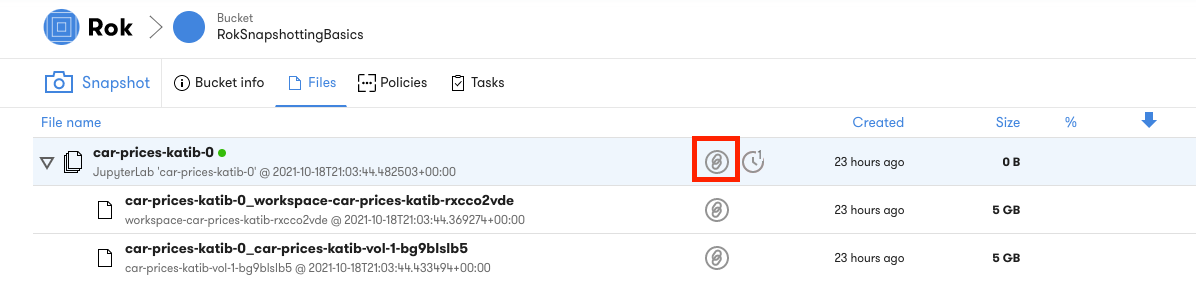
Rok snapshots provide the ability to version entire environments much in the same way that you can version code with Git. Rok snapshots enable you to iterate on your environment as you transform datasets, develop models, and develop other aspects of an ML workflow. The pipeline is always reproducible, thanks to the immutable snapshots, and you do not have to build new Docker images for each pipeline run. To view the snapshots select a specific bucket from the Rok UI. Rok enables restoring snapshots in their entirety on new notebook servers. This enables you to recreate a complete environment exactly the way it was at any point in time. To do this you need to copy the URL from the Rok snapshot.
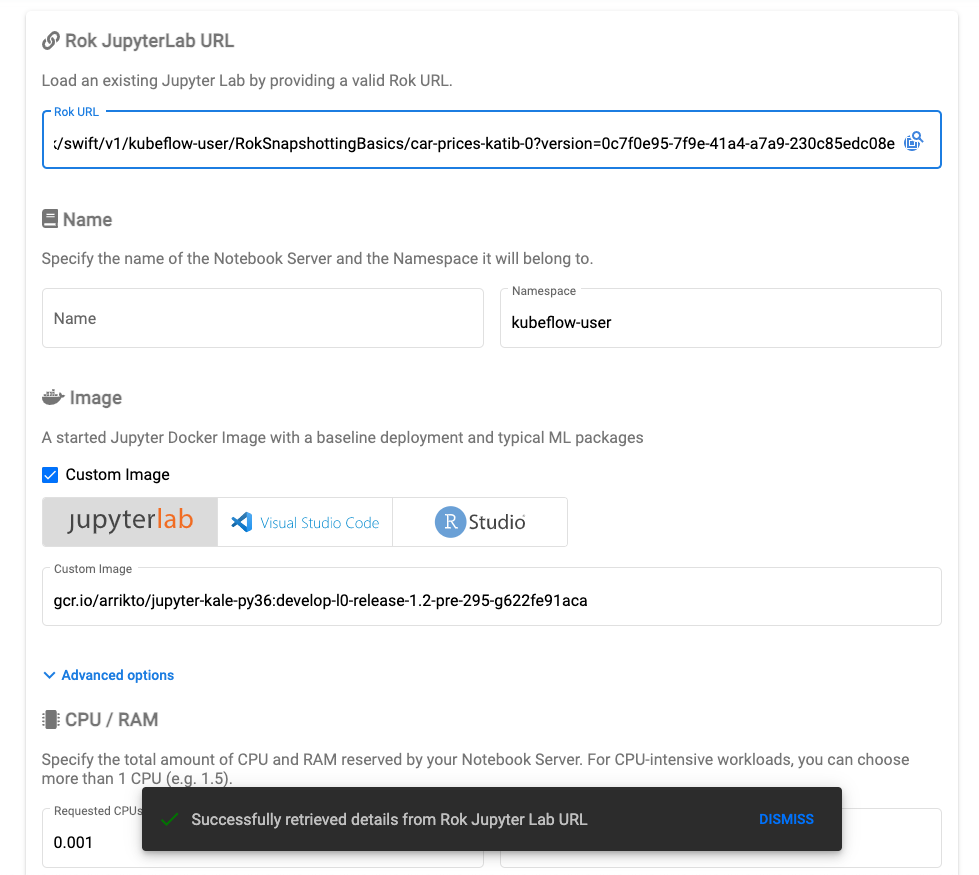
With the URL copied you can provide the Rok snapshot as reference when creating a new notebook server. If the URL is accepted you will see a notification as shown in the image below:
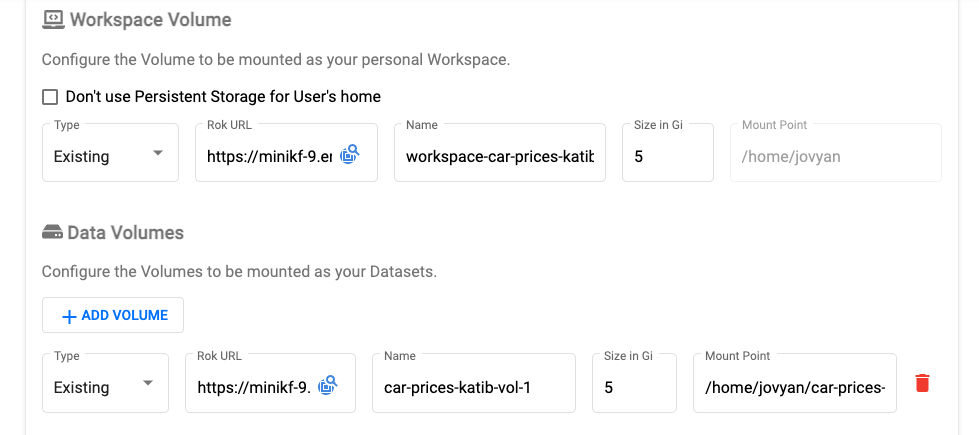
You can confirm that the Rok snapshot was successfully loaded by scrolling down to the workspace volume and data volume, which will be pre-populated based on the data in the snapshot.
Note
If you are creating a notebook server and realize you do not have the Rok URL readily available, you can select the Rok search icon in the Rok URL box. This will open a pop-out window with the available buckets and snapshots from which you can select a notebook snapshot.
Rok Snapshots and Volume Restoration¶
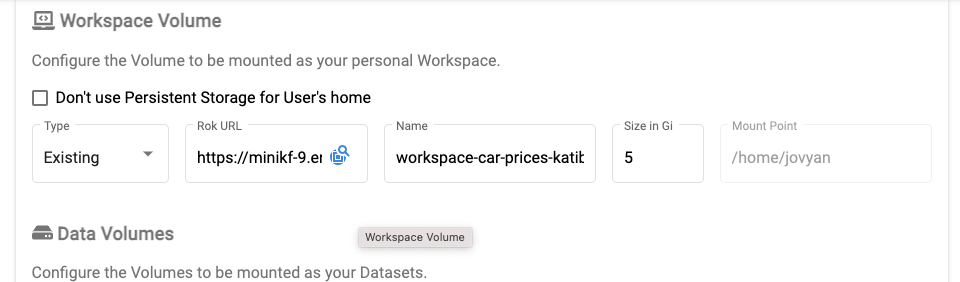
Rok permits loading specific volumes from snapshots during creation of the notebook server. This can be done with either the workspace volume or the data volume. As with the entire snapshot each of the volumes has a specific URL with the workspace volume always first in the list of snapshot volumes.
To populate either volume during notebook server creation you will need to change the option from New to Existing and paste the URL.
Note
If you are creating a notebook server and realize you do not have the URL for the volume readily available, you can select the Rok search icon in the Rok URL box. This will open a pop-out window with the available buckets and snapshots from which you can select a volume. Once you have launched the notebook server you will see preloaded assets based on your selections.
Rok Snapshots and Pipeline Restoration¶
Rok permits loading the snapshot taken before or after the execution of pipeline steps into a notebook server to recreate the captured execution state. The snapshot and the associated URL can be accessed from the snapshot in the Rok UI link under the Visualizations option in the KFP UI.
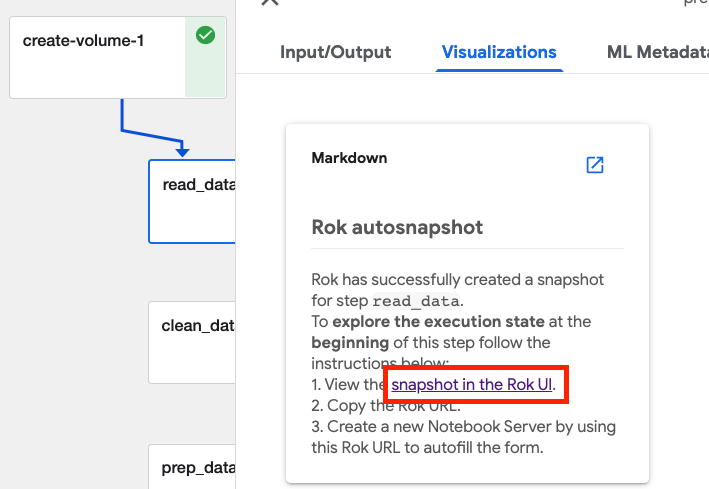
The Rok UI will open to the appropriate snapshot and you can select the Rok snapshot URL.
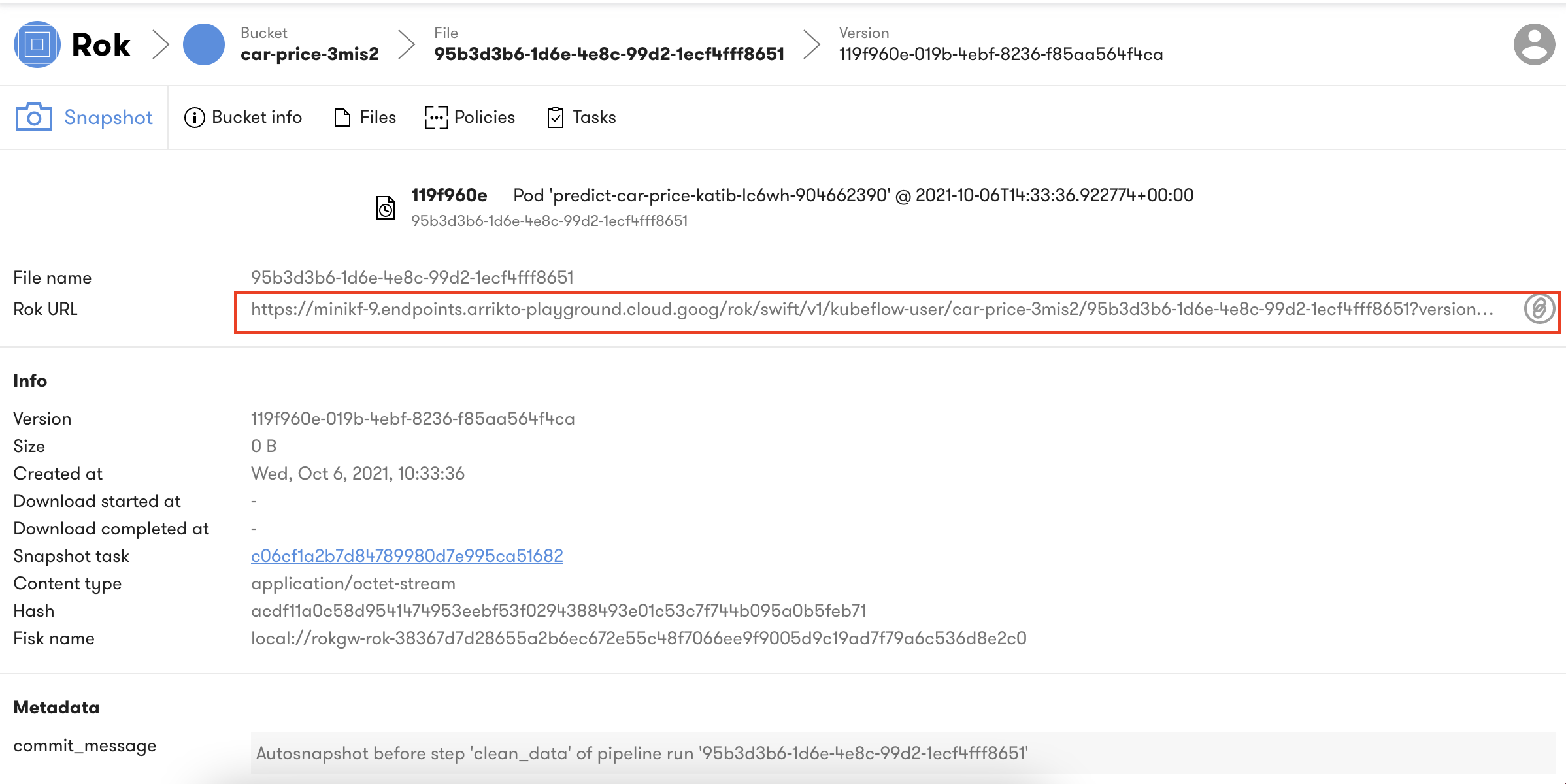
Once you have copied the URL you can use it to recreate the execution state of the pipeline step when creating a notebook server.