
Log Model¶
This section will guide you through logging a Machine Learning (ML) model in MLMD.
Overview
What You’ll Need¶
- An Arrikto EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how the Kale SDK works.
Procedure¶
Create a new notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or EKF release.Connect to the server, open a terminal, and create a new Python file. Name it
log_model.py:$ touch log_model.pyCopy and paste the following code inside
log_model.py:starter.py
1 # Copyright © 2021 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script trains an ML pipeline to solve a binary classification task. 6 """ 7 8 from kale.sdk import pipeline, step 9 from sklearn.datasets import make_classification 10 from sklearn.linear_model import LogisticRegression 11 from sklearn.model_selection import train_test_split 12 13 14 @step(name="data_loading") 15 def load(random_state): 16 """Create a random dataset for binary classification.""" 17 rs = int(random_state) 18 x, y = make_classification(random_state=rs) 19 return x, y 20 21 22 @step(name="data_split") 23 def split(x, y): 24 """Split the data into train and test sets.""" 25 x, x_test, y, y_test = train_test_split(x, y, test_size=0.1) 26 return x, x_test, y, y_test 27 28 29 @step(name="model_training") 30 def train(x, y, training_iterations): 31 """Train a Logistic Regression model.""" 32 iters = int(training_iterations) 33 model = LogisticRegression(max_iter=iters) 34 model.fit(x, y) 35 return model 36 37 38 @pipeline(name="binary-classification", experiment="kale-tutorial") 39 def ml_pipeline(rs=42, iters=100): 40 """Run the ML pipeline.""" 41 x, y = load(rs) 42 x, x_test, y, y_test = split(x, y) 43 train(x, y, iters) 44 45 46 if __name__ == "__main__": 47 ml_pipeline(rs=42, iters=100) Create a new step function which logs an
SklearnModelartifact, using the Kale API:final.py
1 # Copyright © 2021 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-4 4 5 This script trains an ML pipeline to solve a binary classification task. 6 """ 7 8 + from kale.ml import Signature 9 from kale.sdk import pipeline, step 10 + from kale.common import mlmdutils, artifacts 11 from sklearn.datasets import make_classification 12 from sklearn.linear_model import LogisticRegression 13 from sklearn.model_selection import train_test_split 14-36 14 15 16 @step(name="data_loading") 17 def load(random_state): 18 """Create a random dataset for binary classification.""" 19 rs = int(random_state) 20 x, y = make_classification(random_state=rs) 21 return x, y 22 23 24 @step(name="data_split") 25 def split(x, y): 26 """Split the data into train and test sets.""" 27 x, x_test, y, y_test = train_test_split(x, y, test_size=0.1) 28 return x, x_test, y, y_test 29 30 31 @step(name="model_training") 32 def train(x, y, training_iterations): 33 """Train a Logistic Regression model.""" 34 iters = int(training_iterations) 35 model = LogisticRegression(max_iter=iters) 36 model.fit(x, y) 37 return model 38 39 40 + @step(name="register_model") 41 + def register_model(model, x, y): 42 + mlmd = mlmdutils.get_mlmd_instance() 43 + 44 + signature = Signature( 45 + input_size=[1] + list(x[0].shape), 46 + output_size=[1] + list(y[0].shape), 47 + input_dtype=x.dtype, 48 + output_dtype=y.dtype) 49 + 50 + model_artifact = artifacts.SklearnModel( 51 + model=model, 52 + description="A simple Logistic Regression model", 53 + version="1.0.0", 54 + author="Kale", 55 + signature=signature, 56 + tags={"app": "kale-tutorial"}).submit_artifact() 57 + 58 + mlmd.link_artifact_as_output(model_artifact.id) 59 + 60 + 61 @pipeline(name="binary-classification", experiment="kale-tutorial") 62 def ml_pipeline(rs=42, iters=100): 63 """Run the ML pipeline.""" 64 x, y = load(rs) 65 x, x_test, y, y_test = split(x, y) 66 - train(x, y, iters) 67 + model = train(x, y, iters) 68 + register_model(model, x, y) 69 70 71 if __name__ == "__main__": 72 ml_pipeline(rs=42, iters=100) Warning
Running this pipeline in an environment that cannot communicate with Rok will result in an error. This is because Kale needs to take a snapshot of the mounted volumes in order to store the artifact’s object.
Refer to Kale’s MLMD API docs for more information.
Deploy and run your code as a KFP pipeline:
$ python3 -m kale log_model.py --kfpFrom the EKF central dashboard select Runs to view the KFP run you just created.
View the logged model in MLMD.
Once the pipeline completes, click on the step register_model. Then, click on the ML Metadata tab on the panel that opened on the right. Scroll down to the bottom.
You will notice a
kale.Modelartifact registered as an output of your step. You can click on the Name of the artifact to open the MLMD page which provides more metadata.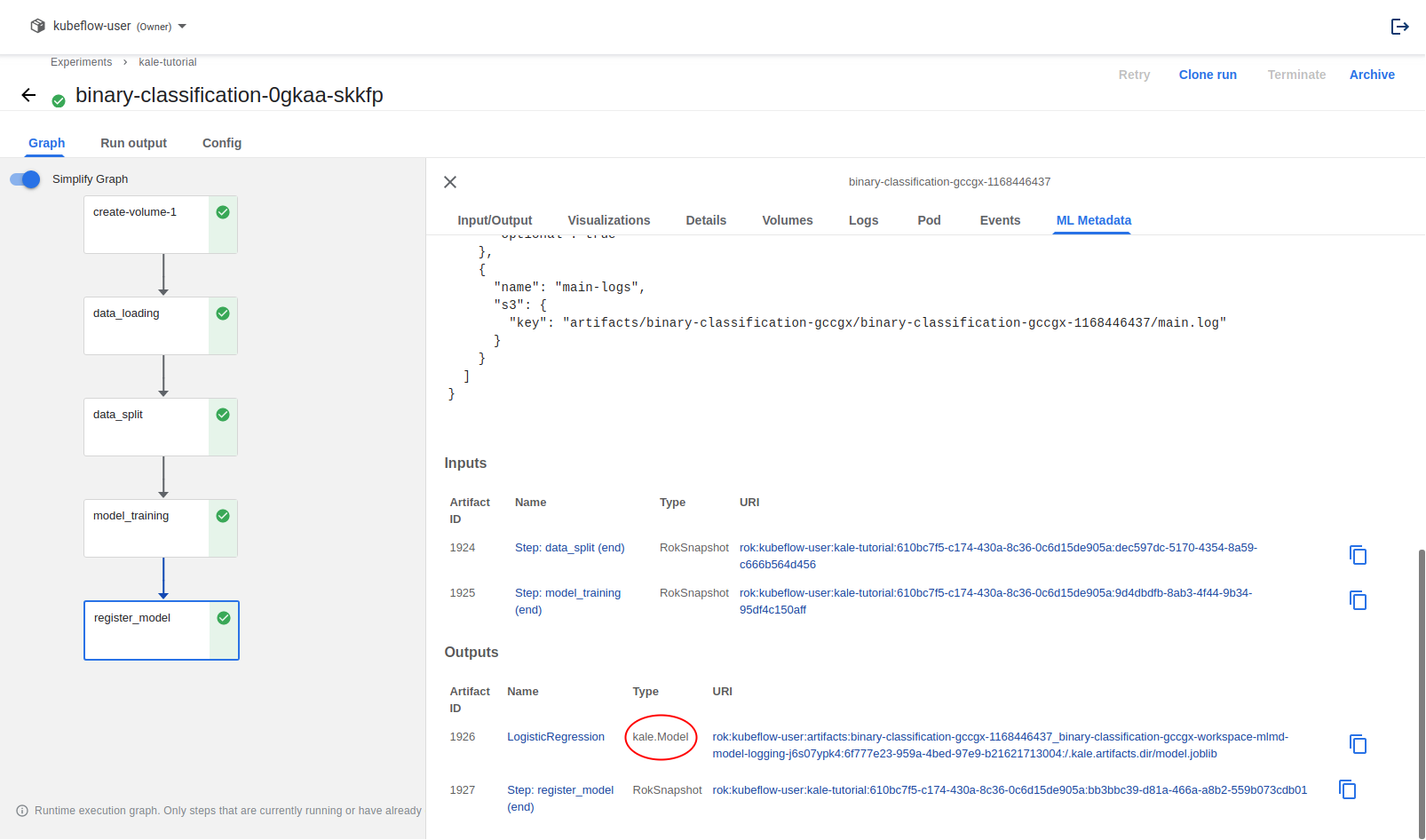
Note
Arrikto is working on a brand new MLMD and Model Registry UI that will greatly improve the UX experience of searching and managing your model artifacts.
Note
For more details on how you can create and submit model artifacts, refer to the MLMD API docs.