
Serving Architecture¶
In Arrikto EKF, all serving components, including user-created inference services, are part of the Istio mesh and as such, run with an Istio sidecar and use Istio mTLS. This allows for encrypted intra-pod traffic and fine-grained authorization policies.
See also
We opted to isolate serving components from EKF ones by using a dedicated load balancer, NGINX ingress controller, and Istio ingress gateway (IGW) so that you can
- expose serving differently, for example have it publicly available while EKF remains private, and
- have a different authentication mechanism than the one on EKF.
Important
Authentication will be enabled by default (similar to EKF), and users will be able to access their models using an external client. Currently all authenticated users will be able to access all models inside the cluster.
Overview
Request Path¶
An inference service is accessible via two URLs:
- The internal one, which can be used by clients running in the same cluster.
- The external one, which can be used by clients running outside the cluster.
Below, we will analyze the request path of a programmatic client requesting a
prediction from a model for both options. Our examples assume a simple inference
service with a Triton server as predictor, serving a TensorFlow model trained
with the MNIST dataset, and hey as the client that hits the inference
service.
Our examples use the following prediction URLs:
- Internal URL:
http://tf-triton-mnist.kubeflow-user.svc.cluster.local/v2/models/tf-triton-mnist/infer - External URL:
https://tf-triton-mnist-kubeflow-user.serving.example.com/v2/models/tf-triton-mnist/infer
Internal Client¶
Internal clients run in the same cluster as the inference service. For example, they can run in a Pod in the same namespace as the inference service. These clients can use the internal URL to reach the served model.

Here is a step-by-step description of how prediction works in case of an internal client using the internal URL:
Client: Make a POST request using the URL that the inference service reports, that is,
http://tf-triton-mnist.kubeflow-user.svc.cluster.local/v2/models/tf-triton-mnist/infer.This request reaches Knative local IGW since ExternalName Service tf-triton-mnist points to the knative-serving-cluster-ingressgateway Deployment.
Local IGW: Serve the request based on VirtualService tf-triton-mnist.
Istio serves this request since VirtualService tf-triton-mnist matches host tf-triton-mnist.kubeflow-user.svc.cluster.local. Istio sets the
Hostheader totf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.localand routes the request to knative-serving-cluster-ingressgateway.knative-serving.Local IGW: Serve the request based on VirtualService tf-triton-mnist-predictor-default-ingress.
Istio serves this request since VirtualService tf-triton-mnist-predictor-default-ingress matches host tf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.local. Istio sets the
Hostheader totf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.localand routes the request to tf-triton-mnist-predictor-default-00001.kubeflow-user.svc.cluster.local. The request reaches the activator Pod, since the ClusterIP Service, named tf-triton-mnist-predictor-default-00001, exists with the corresponding endpoints that point to the activator Pod of Knative instead of the predictor Pod.Knative Activator: Proxy the request to predictor Pods using the Knative private endpoint, that is,
http://tf-triton-mnist-predictor-default-00001-private.kubeflow-user/v2/models/tf-triton-mnist/infer.Kubernetes routes the request to the queue-proxy of the predictor Pod since the ClusterIP Service tf-triton-mnist-predictor-default-00001-private maps port
80to port8012, where queue-proxy sidecars listens on.Predictor - istio-proxy: Allow the request since the AuthorizationPolicy knative-serving exists.
Predictor - queue-proxy: Proxy the request locally to the Triton server on port
8080after increasing Knative metrics.Predictor - kfserving-container: Triton responds to the POST request with a prediction.
External Client¶
Clients running outside the cluster use the external URL of the inference service. EKF will authenticate incoming requests before reaching the predictor Pods.
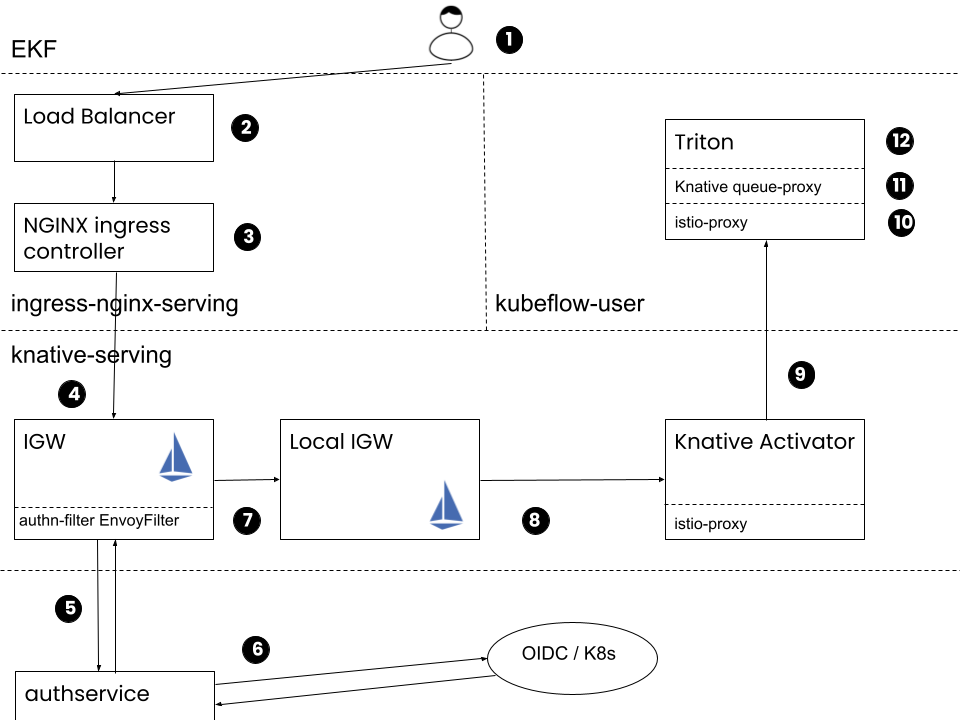
Here is a step-by-step description of how prediction works in case of an external client that uses the external URL:
Client: Make a POST request using the URL that inference service reports, that is,
https://tf-triton-mnist-kubeflow-user.serving.example.com/v2/models/tf-triton-mnist/infer.Cloud Load Balancer: Receive the request and proxy it to the NGINX that EKF uses for serving.
On EKS, for example, the Load Balancer is either an ALB (Ingress) or a classic ELB (Service) that forwards all traffic to the NGINX that EKF uses for serving.
NGINX Ingress Controller: Proxy the request to Istio IGW that EKF uses for serving.
A knative-serving-ingress Ingress of type nginx-serving exists and proxies all
*.serving.example.comtraffic to the Istio IGW that EKF uses for serving.Istio IGW: Receive and authenticate the request.
Istio uses the EnvoyFilter authn-filter to check if the request is authenticated, by making a request to the AuthService and passing the
authorization,cookie, andx-auth-tokenheaders of the original request.AuthService: Check if the request is authenticated based on the request headers.
In case of service account token authentication, AuthService will make a
SubjectAccessReviewrequest to the Kubernetes API server. If the request is authenticated, it will respond by setting thekubeflow-useridandkubeflow-groupsheaders.IGW: Serve the request based on VirtualService tf-triton-mnist.
Istio serves this request since VirtualService tf-triton-mnist matches host tf-triton-mnist-kubeflow-user.serving.example.com. Istio sets
Hostheader totf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.localand routes the request to knative-serving-cluster-ingressgateway.knative-serving.Local IGW: Serve the request based on VirtualService tf-triton-mnist-predictor-default-ingress.
Istio serves this request since VirtualService tf-triton-mnist-predictor-default-ingress matches host tf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.local. Istio sets
Hostheader totf-triton-mnist-predictor-default.kubeflow-user.svc.cluster.localand routes the request to tf-triton-mnist-predictor-default-00001.kubeflow-user.svc.cluster.local. The request reaches the activator Pod, since the ClusterIP Service, named tf-triton-mnist-predictor-default-00001, exists with the corresponding endpoints that point to the activator Pod of Knative instead of the predictor Pod.Knative Activator: Proxy the request to predictor Pods using the Knative private endpoint, that is,
http://tf-triton-mnist-predictor-default-00001-private.kubeflow-user/v2/models/tf-triton-mnist/infer.Kubernetes routes the request to the queue-proxy of the predictor Pod since the ClusterIP Service tf-triton-mnist-predictor-default-00001-private maps port
80to port8012, where queue-proxy sidecars listens on.Predictor - istio-proxy: Allow the request since the AuthorizationPolicy knative-serving exists.
Predictor - queue-proxy: Proxy the request locally to the Triton server on port
8080after increasing Knative metrics.Predictor - kfserving-container: Triton responds to the POST request with a prediction.
Using Activator Only When Scaled to Zero¶
The activator is responsible for receiving and buffering requests for inactive revisions, and reporting metrics to the Autoscaler. It also retries requests to a revision after the Autoscaler scales the revision based on the reported metrics.
The activator may be in the path, depending on the revision scale and load, and the given target burst capacity. By default, the activator is in the path and may become the bottleneck. If you don’t need to limit the concurrency of requests arriving to your model, you can have the activator in the request path only when scaled to zero. How models are scaled up and down is a matter of configuring autoscaling and setting the soft limit for the concurrency.
See also
Note
Removing the activator from the path results in an inability to impose a hard concurrency limit. This is the default behavior, that is, there is no limit on the number of requests that are allowed to flow into the revision.
What’s Next¶
The next step is to configure Serving for better performance.