
Prepare Your Notebook¶
To perform hyperparameter tuning using Katib and Kale you will need to prepare your notebook as follows.
- Identify a model to optimize.
- Create a Pipeline Parameters cell.
- Create a Pipeline Metrics cell.
See Hyperparameter Tuning for more detail on hyperparameters metrics and other key concepts.
Identify a Model¶
Initially, you will often compare multiple models as you experiment to build your machine learning pipeline. However, typically, you will perform hyperparameter tuning on only the model with the greatest accuracy in validation tests.
Select the Best Performing Model¶
To select the best performing model, you can view the output from an evaluation step in your pipeline using the Kale UI. The easiest way to do this is to review the logs from a pipeline run. Follow the steps below to view the logs.
View the graph from your pipeline run.
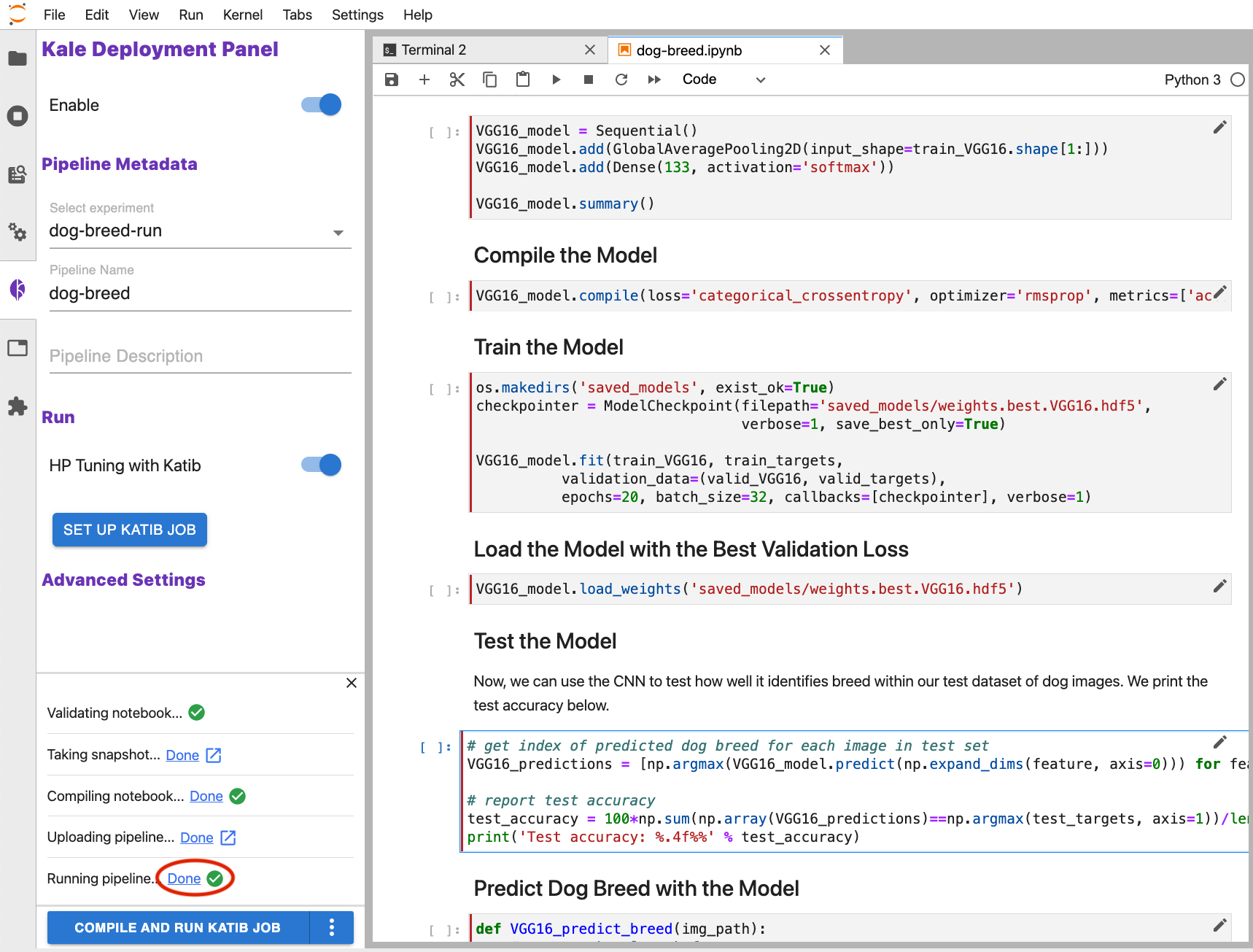
Click on the pipeline step that produces the output you want to view.
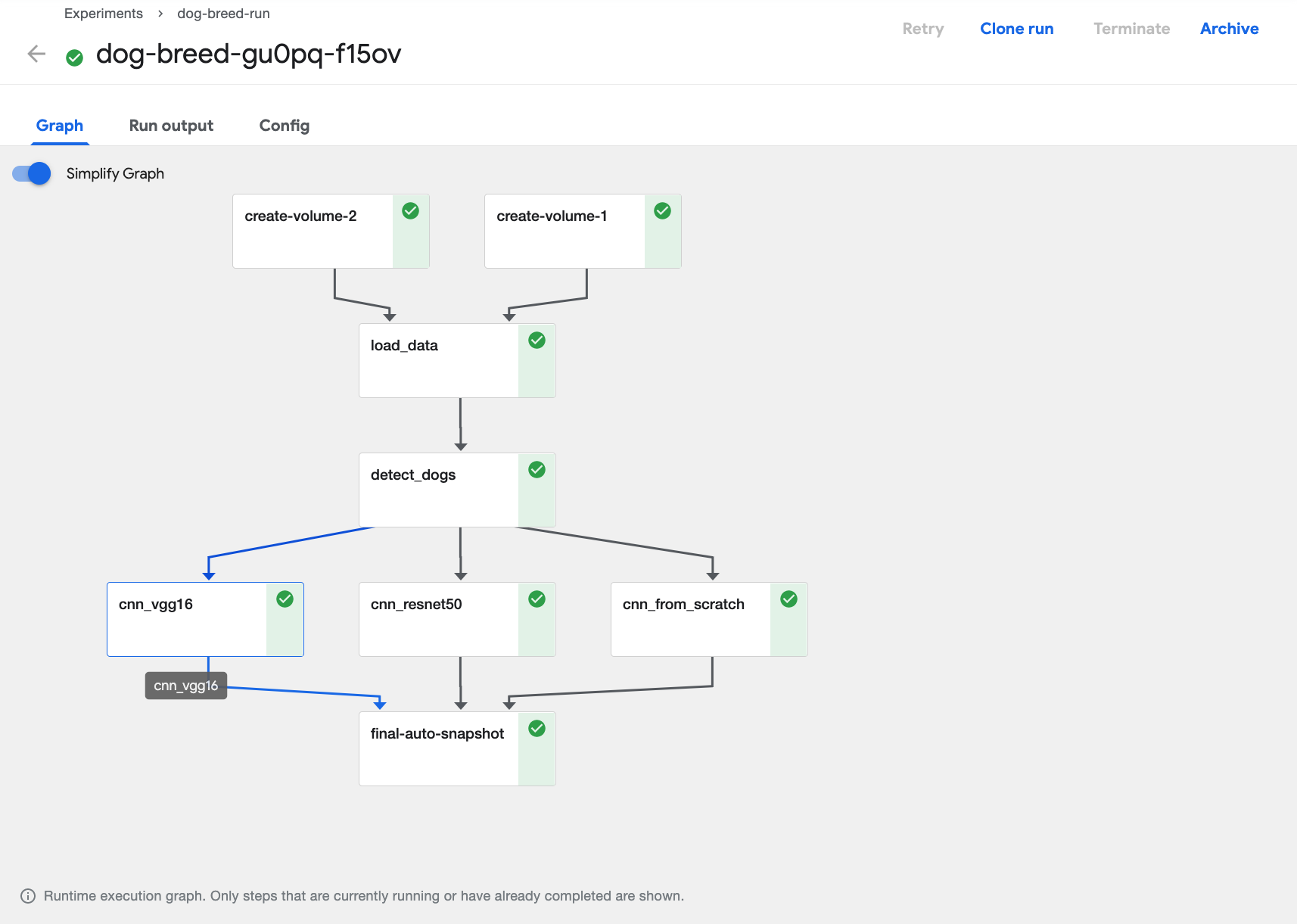
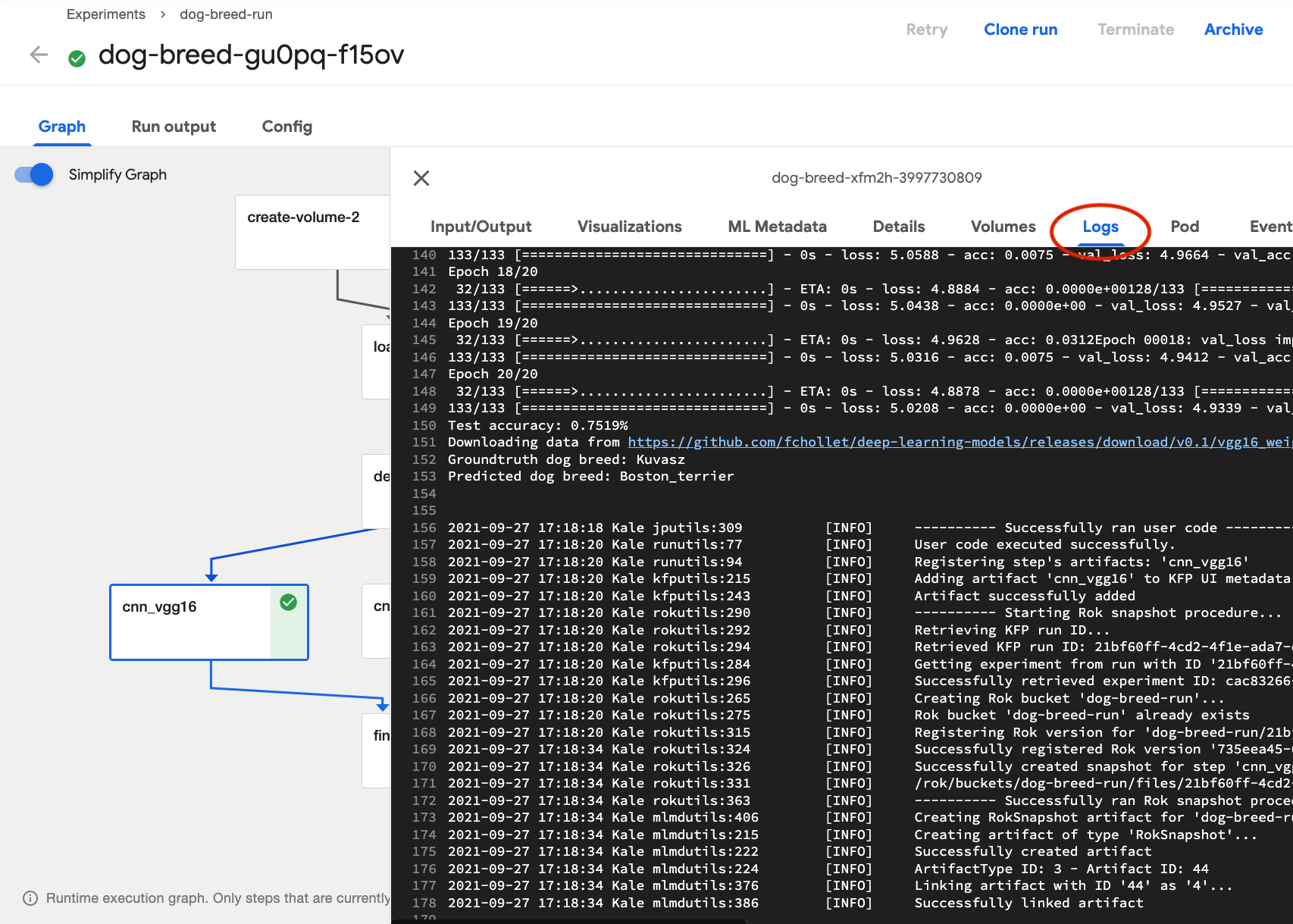
Select the logs tab.
Note
Depending on how your pipeline is defined, you might need to view the logs for multiple steps in order to assess the relative performance of two or more models.
Exclude Other Models¶
So that your Katib experiments run as efficiently as possible, once you’ve identified a model to optimize with hyperparameter tuning, annotate cells associated with any other models using the Skip Cell label. This will exclude those cells from the pipeline Kale creates. Excluding cells associated with other models will reduce the size of the KubeFlow pipeline that is created for Katib experiments and, thereby, speed up the hyperparameter tuning process.
See Skip Cells for instructions on excluding cells from a pipeline using the Kale UI.
Pipeline Parameters Cells¶
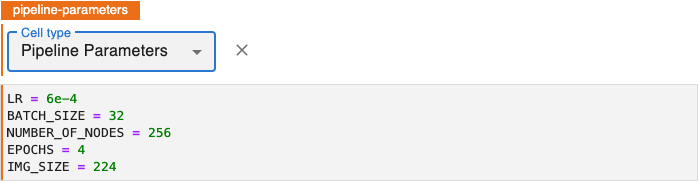
Annotate notebook cells as Pipeline Parameters to identify blocks of code that define variables to be used as hyperparameters. These should be values that you might experiment with as you evaluate the relative performance of a pipeline run with different hyperparameter values.
Hyperparameters¶
Hyperparameters are variables that control a model training process. They include:
- The learning rate.
- The number of layers in a neural network.
- The number of nodes in each layer.
Hyperparameter values are not learned. In contrast to the node weights and other training parameters, a model training process does not adjust hyperparameter values.
See Hyperparameter Tuning for more detail on hyperparamaters metrics and other key concepts.
Purpose¶
Kale uses the values in Pipeline Parameters cells to define Kubeflow Pipeline
(KFP) PipelineParam objects and initializes the KF Pipeline with these
parameters. KFP includes pipeline parameters values in the artifacts it creates
for pipeline runs to facilitate review of results from experiments comparing
multiple runs of a pipeline.
Annotate Pipeline Parameters Cells¶
To annotate pipeline parameters, edit the first cell containing pipeline parameters by clicking the pencil icon in the upper right corner and select Cell type > Pipeline Parameters.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
Pipeline Metrics Cells¶
Annotate a notebook cell with the label Pipeline Metrics to identify code that outputs the results you want to evaluate for a pipeline run. Kale enables you to perform hyperparameter tuning using Katib in order to optimize a model based on a selected pipeline metric. In order to perform Katib experiments, organize all pipeline metrics into a single cell and annotate the cell using the Pipeline Metrics.
Purpose¶
Based on the variables referenced in a Pipeline Metrics cell, Kale will define pipeline metrics that the Kubeflow Pipelines (KFP) system will produce for every pipeline run. In addition, Kale will associate each one of these metrics to the steps that produced them.
Pipeline metrics are key to the AutoML capabilities of Kubeflow and Kale. You will need to choose a single pipeline metric as the search objective metric for hyperparameter tuning experiments. Tracking pipeline metrics is essential to evaluating performance across multiple runs of a pipeline that have been parameterized differently or modified while still in the experimental phase of developing a model.
Annotate Pipeline Metrics Cell¶
Note
Pipeline metrics should be considered the result of pipeline execution, not the result of an individual step. You should only annotate one cell with Pipeline Metrics and that cell should be the last cell in your notebook.
To identify pipeline metrics, edit the cell containing pipeline metrics statements by clicking the pencil icon in the upper right corner and select Cell type > Pipeline Metrics.
Note
If you don’t see the pencil icon, please enable Kale from the Kale Deployment Panel.
