
Serve Model Artifact ID with Custom Transformer¶
This section will guide you through serving a model using a model artifact ID,
with a custom transformer, using the Kale serve API.
- An Arrikto EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how you can define a ServeConfig object.
- An understanding of how the Kale Serve API works.
- A custom transfromer image.
Procedure¶
This guide comprises three sections: in the first section, you will create a
model which you will register to MLMD to get its artifact ID. Then, in the
second section, you will use Kale serve API to serve your model along with a
custom transformer. Finally, in the third section, you will invoke the custom
model service to get predictions.
Create Model Artifact ID¶
Create a new notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or Arrikto EKF release.Open a terminal and install the XGBoost python library:
$ pip3 install xgboost==1.5.2Open a terminal and create a new Python file named
create_model_artifact.py:jovyan@notebook:~$ touch create_model_artifact.pyCopy and paste the following code inside
create_model_artifact.py:custom_model_artifact.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script uses an ML pipeline to create a model artifact ID for an XGBoost 6 model. 7 """ 8 9 import xgboost as xgb 10 11 from typing import Tuple 12 13 from sklearn.model_selection import train_test_split 14 from sklearn.datasets import fetch_california_housing 15 16 from kale.ml import Signature 17 from kale.types import MarshalData 18 from kale.sdk import pipeline, step 19 from kale.common import mlmdutils, artifacts 20 21 22 @step(name="data_loading") 23 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 24 """Fetch California Housing dataset.""" 25 # get data and target of the dataset 26 california_housing = fetch_california_housing() 27 x = california_housing.data 28 y = california_housing.target 29 30 # split the dataset 31 x_train, _, y_train, _ = train_test_split(x, y, test_size=.2, 32 random_state=42) 33 return x_train, y_train 34 35 36 @step(name="model_training") 37 def train(x: MarshalData, y: MarshalData) -> MarshalData: 38 """Train a XGBRegressor model.""" 39 model = xgb.XGBRegressor(objective='reg:squarederror', 40 colsample_bytree=1, 41 eta=0.3, 42 learning_rate=0.1, 43 max_depth=5, 44 alpha=10, 45 n_estimators=2000) 46 model.fit(x, y) 47 return model 48 49 50 @step(name="register_model") 51 def register_model(model: MarshalData, x: MarshalData, y: MarshalData): 52 mlmd = mlmdutils.get_mlmd_instance() 53 54 signature = Signature( 55 input_size=[1] + list(x[0].shape), 56 output_size=[1] + list(y[0].shape), 57 input_dtype=x.dtype, 58 output_dtype=y.dtype) 59 60 model_artifact = artifacts.XGBoostModel( 61 model=model, 62 description="A simple XGBRegressor model", 63 version="1.0.0", 64 author="Kale", 65 signature=signature, 66 tags={"app": "xgboost"}).submit_artifact() 67 68 mlmd.link_artifact_as_output(model_artifact.id) 69 return 70 71 72 @pipeline(name="regression", experiment="xgboost") 73 def ml_pipeline(): 74 """Run the ML pipeline.""" 75 x_train, y_train = load_split_dataset() 76 model = train(x_train, y_train) 77 register_model(model, x_train, y_train) 78 79 80 if __name__ == "__main__": 81 ml_pipeline() This script defines a KFP run using the Kale SDK. Specifically, it defines a pipeline that creates the model artifact.
Deploy and run your code as a KFP pipeline:
jovyan@notebook:~$ python3 -m kale create_model_artifact.py --kfpSelect Runs to view the KFP run you just created. This is what it looks like when the pipeline completes successfully:
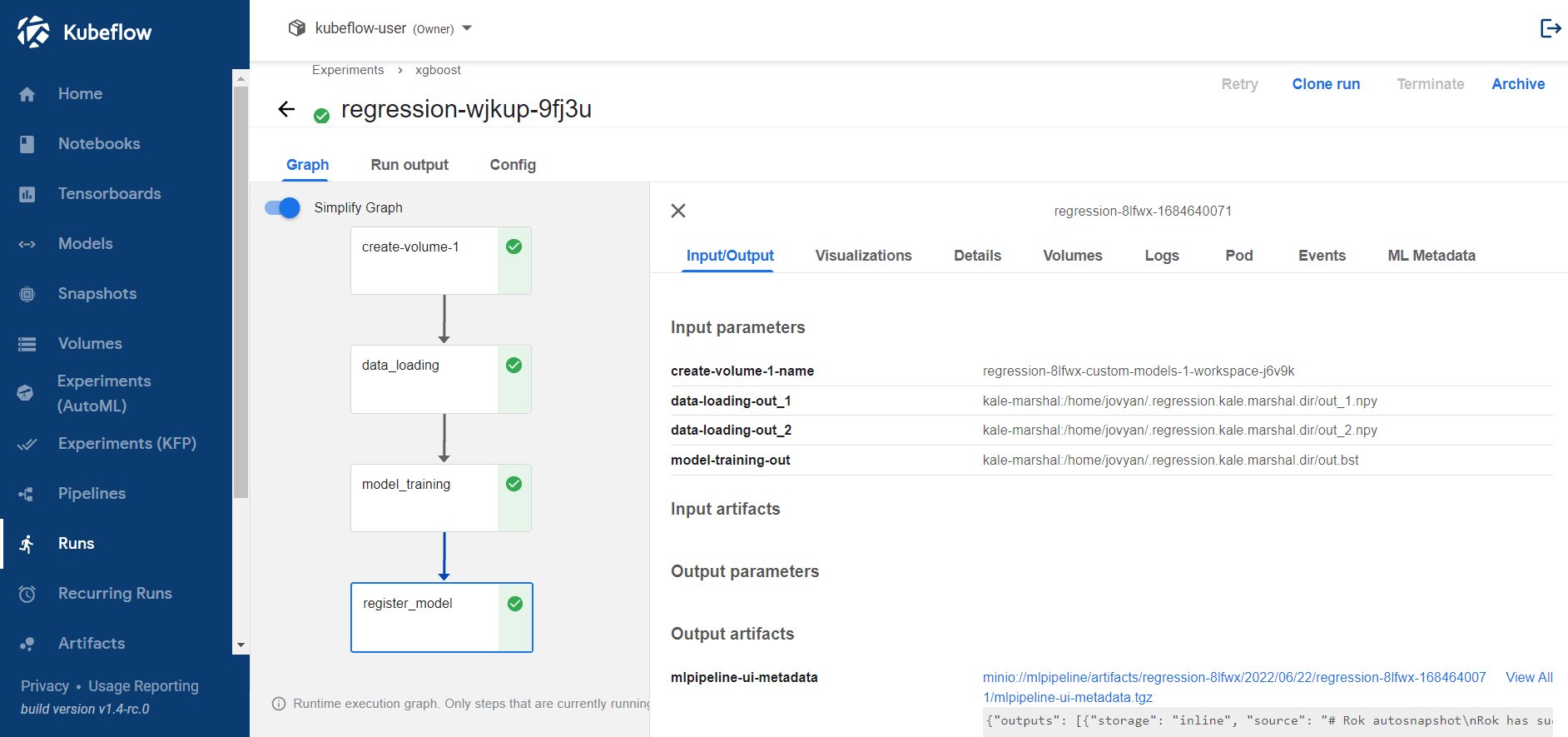
Wait until the pipeline completes. Check the ML Metadata tab of the
create_artifactstep to retrieve the model artifact iD.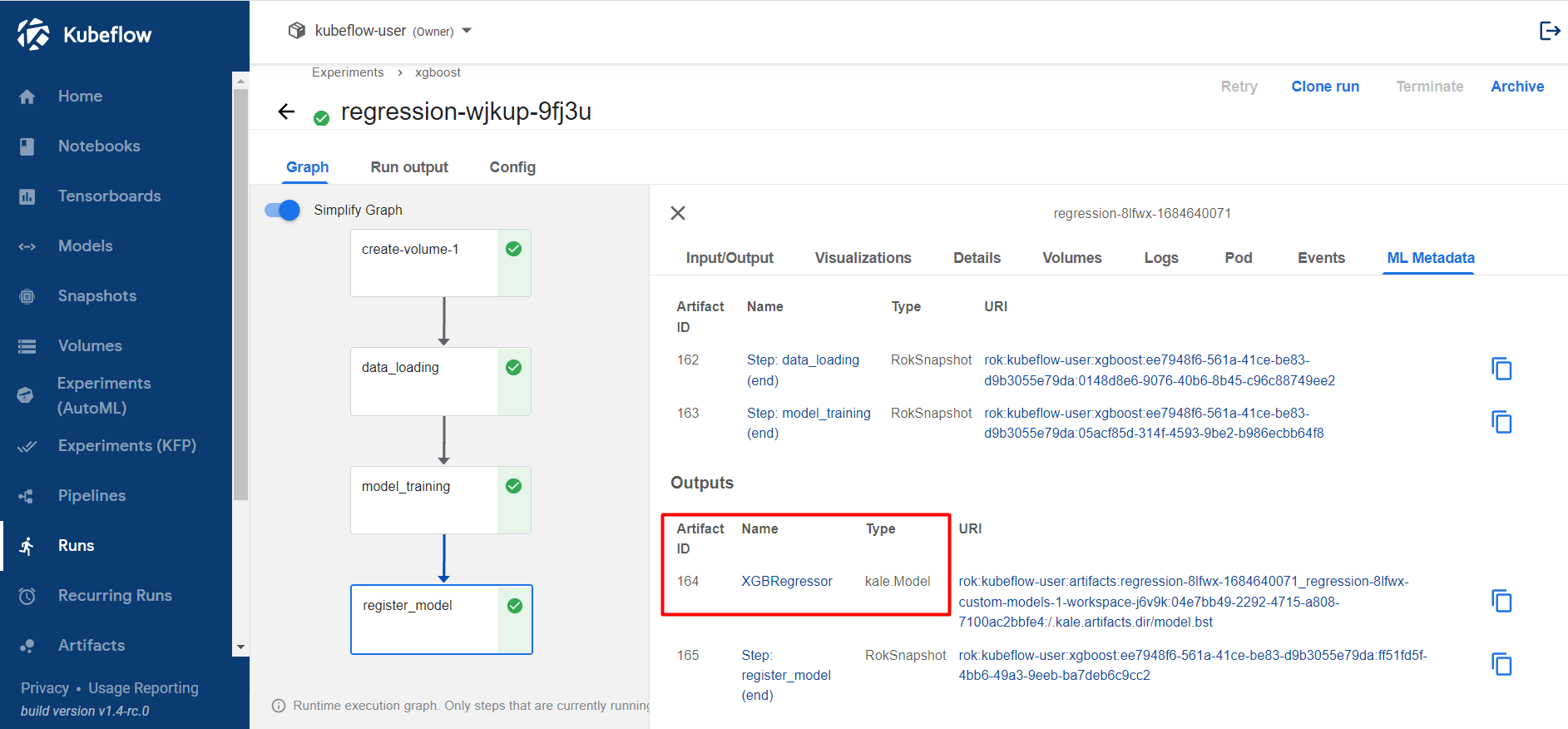
Serve Model¶
In the existing notebook server, create a new Jupyter notebook (that is, an IPYNB file):

Use the Kale
serveAPI to serve thecustom-model. Copy and paste the the following code in the first code cell:Replace the
<num>with the model artifact ID. In our case is equal to 164. Yours would probably be different.This is how your notebook cell will look like: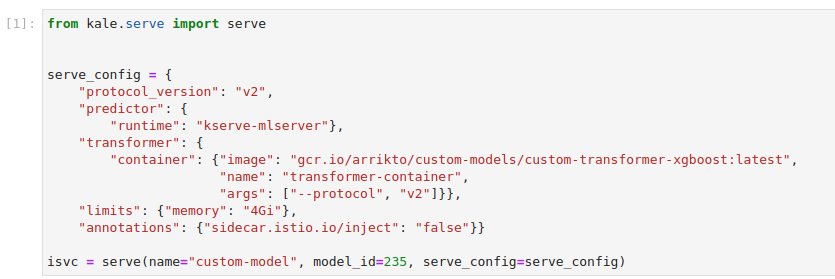
Note
To build the transformer image, you can follow Create Custom Transformer Image and use the following code and requirements:
custom_transformer_xgboost.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """This script defines a custom transformer.""" 4-45 4 5 import kserve 6 from typing import Dict 7 import argparse 8 9 10 class Transformer(kserve.Model): 11 """Define custom transformer.""" 12 13 def __init__(self, model_name: str, predictor_host: str, protocol: str): 14 super().__init__(model_name) 15 self.predictor_host = predictor_host 16 self.protocol = protocol 17 18 def preprocess(self, request: Dict): 19 return request 20 21 def postprocess(self, request: Dict) -> Dict: 22 value = request["outputs"][0]["data"][0] 23 request["outputs"][0]["data"][0] = round(value * 100000, 2) 24 return request 25 26 27 DEFAULT_MODEL_NAME = "custom-model" 28 DEFAULT_PROTOCOL = "v1" 29 30 parser = argparse.ArgumentParser(parents=[kserve.model_server]) 31 parser.add_argument('--model_name', default=DEFAULT_MODEL_NAME, 32 help='The name that the model is served under.') 33 parser.add_argument('--predictor_host', 34 help='The URL for the model predict function', 35 required=True) 36 parser.add_argument('--protocol', default=DEFAULT_PROTOCOL, 37 help='The predictor protocol version', 38 required=True) 39 40 args, _ = parser.parse_known_args() 41 42 43 if __name__ == "__main__": 44 server = kserve.ModelServer() 45 model = Transformer(model_name=args.model_name, 46 predictor_host=args.predictor_host, 47 protocol=args.protocol) 48 server.start(models=[model]) custom_transformer_xgboost_req.txt
1 kserve==0.8.0 2 ray<1.7.0 3 protobuf==3.19.3 4 tornado==6.1
Get Predictions¶
In this section, you will query the model endpoint to get predictions.
In the existing Notebook, in a different code cell, initialize a Kale
Endpointobject using the name of the InferenceService:This is how your notebook cell will look like:

Note
When initializing an
Endpoint, you can also pass the namespace of the InferenceService. For example, if your namespace ismy-namespace:If you do not provide one, Kale assumes the namespace of the notebook server. In our case it is
kubeflow-user.This is how your notebook cell will look like:
Invoke the server to get predictions. Copy and paste the following snippet in a different code cell and run it:
This is how your notebook cell will look like:
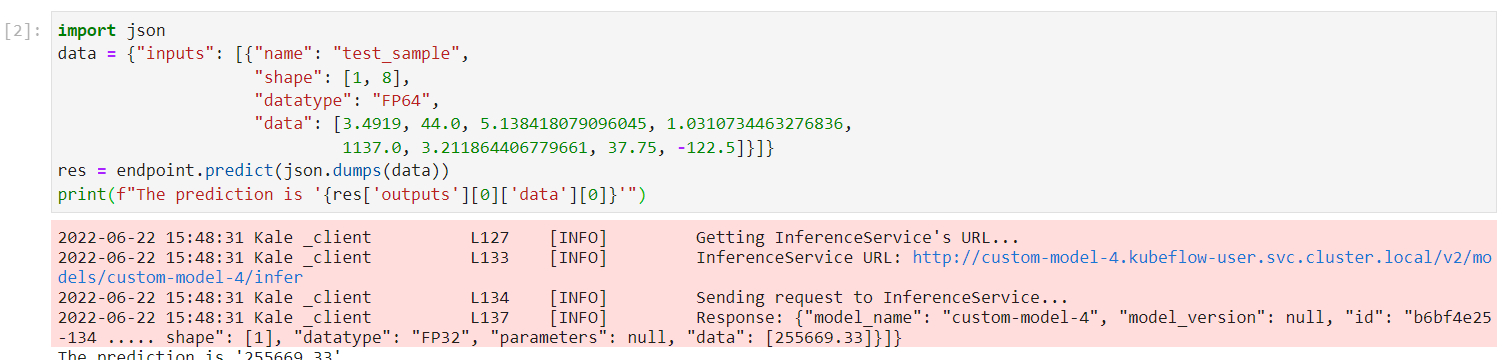
Summary¶
You have successfully served a model registered to MLMD along with a custom
transformer endpoint using the Kale serve API.
What’s Next¶
Check out how you can configure the deployment of the model you are serving on Kubernetes.