Serve TensorFlow Models¶
This section will guide you through serving a TensorFlow model, using the Kale
serve API.
Overview
What You’ll Need¶
- An Arrikto EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how the Kale SDK works.
- An understanding of how the Kale serve API works.
Procedure¶
This guide comprises three sections: In the first section, you will explore and process the dataset. Then, in the second section, you will leverage the Kale SDK to build a Machine Learning (ML) pipeline that trains and serves a TensorFlow model. Finally, in the third section, you will invoke the model service to get predictions on a holdout test subset.
Explore Dataset¶
In this guide, you will work with the CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) Images dataset that contains more than 1000 files. The end goal is to identify the letters in those images. A full description of the example is available in the Keras examples documentation.
Create a new notebook server using the Kale TensorFlow Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-gpu-tf-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or Arrikto EKF release.Note
If you want to have access to a GPU device you must specifically request one or more from the Jupyter Web App UI. For this user guide, access to a GPU device is not required, but we recommend to add one so that you can get better results.
Connect to the Jupyter server, open a terminal window, and install
curl:$ sudo apt update && sudo apt install curl -yCreate a new Jupyter notebook (that is, an IPYNB file):

Download the dataset. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:

Copy and paste the import statements in the next code cell, and run it:
This is how your notebook cell will look like:
Load and explore the dataset. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:
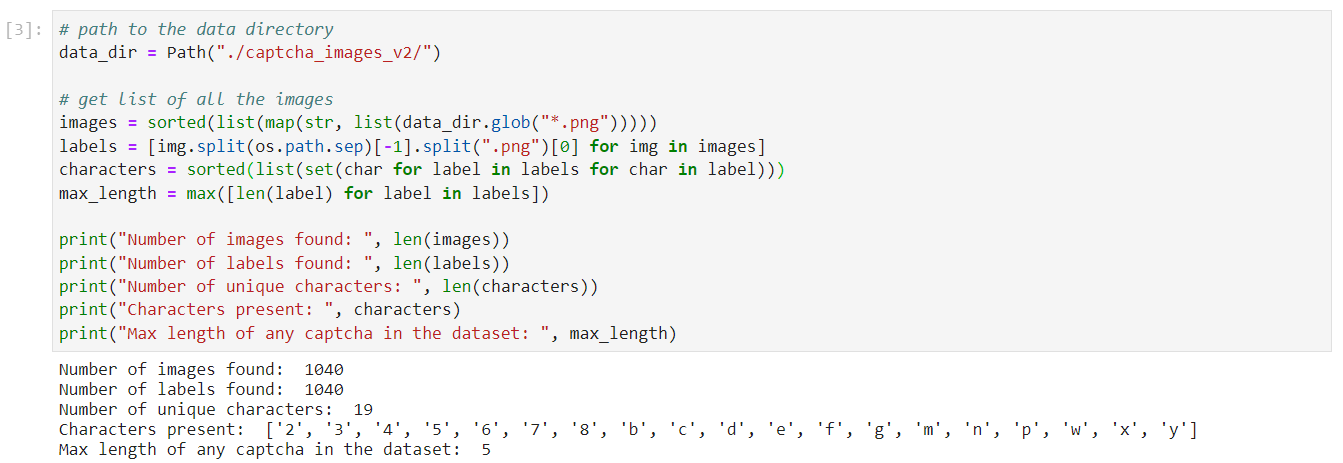
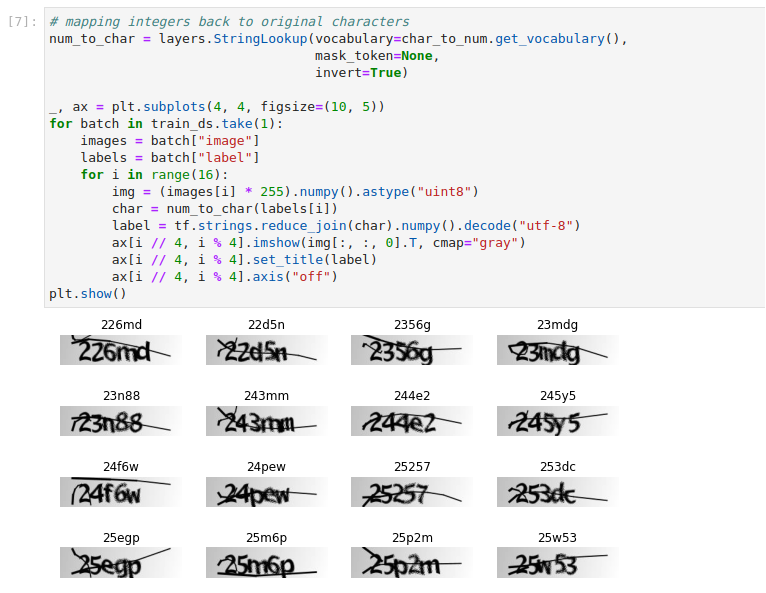
The dataset consists of
1040images with their labels. The labels are strings that the image depicts, usually a few random alphanumeric symbols, and are retrieved from the images file names. Specifically in this example, the labels are5character strings composed of the following characters:'2','3','4','5','6', '7','8','b','c','d','e','f','g','m','n','p','w','x', 'y'.Split the dataset into training and validation subsets. In a new cell, copy and paste the following code, and run it:
This is how your notebook cell will look like:
Preprocess the dataset: Represent each image in greyscale and map the labels’ characters to numbers. Run the following cell to transform the raw training and validation subsets:
This is how your notebook cell will look like:
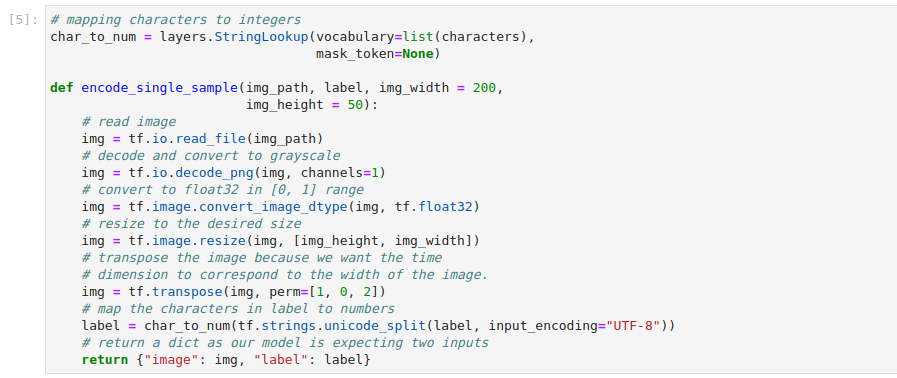
Create the training and validation datasets. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:
Run the following code in a new cell to visualize examples from the training subset:
This is how your notebook cell will look like:
Serve TensorFlow Model¶
In this section, you will build a pipeline that trains a deep neural network to recognize the characters in a CAPTCHA image.
In the same notebook server, open a terminal, and create a new Python file. Name it
serve_tensorflow_model.py:$ touch serve_tensorflow_model.pyCopy and paste the following code inside
serve_tensorflow_model.py:tensorflow_starter.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script uses an ML pipeline to train and serve an Tensorflow Model. 6 """ 7 8 import os 9 10 import numpy as np 11 import tensorflow as tf 12 13 from pathlib import Path 14 from typing import Tuple 15 16 from tensorflow.keras import layers 17 18 from kale.types import MarshalData 19 from kale.sdk import pipeline, step 20 21 22 def _split_data(images, labels, train_size=0.9, shuffle=False): 23 # get the total size of the dataset 24 size = len(images) 25 # make an indices array and shuffle it, if required 26 indices = np.arange(size) 27 if shuffle: 28 np.random.shuffle(indices) 29 # get the size of training samples 30 train_samples = int(size * train_size) 31 # split data into training and validation sets 32 x_train = images[indices[:train_samples]] 33 y_train = labels[indices[:train_samples]] 34 x_valid = images[indices[train_samples:]] 35 y_valid = labels[indices[train_samples:]] 36 return x_train, x_valid, y_train, y_valid 37 38 39 def _get_preprocessed_datasets(x_train, y_train, x_valid, y_valid, 40 batch_size, characters): 41 42 def _encode_single_sample(img_path, label, img_width=200, img_height=50): 43 # read image 44 img = tf.io.read_file(img_path) 45 # decode and convert to grayscale 46 img = tf.io.decode_png(img, channels=1) 47 # convert to float32 in [0, 1] range 48 img = tf.image.convert_image_dtype(img, tf.float32) 49 # resize to the desired size 50 img = tf.image.resize(img, [img_height, img_width]) 51 # transpose the image because we want the time 52 # dimension to correspond to the width of the image. 53 img = tf.transpose(img, perm=[1, 0, 2]) 54 # map the characters in label to numbers 55 label = char_to_num( 56 tf.strings.unicode_split(label, input_encoding="UTF-8")) 57 # return a dict as our model is expecting two inputs 58 return {"image": img, "label": label} 59 60 # mapping characters to integers 61 char_to_num = layers.StringLookup(vocabulary=list(characters), 62 mask_token=None) 63 64 # Training dataset object 65 train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) 66 train_dataset = (train_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 67 .batch(batch_size) 68 .prefetch(buffer_size=tf.data.AUTOTUNE)) 69 70 # Validation dataset object 71 valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)) 72 valid_dataset = (valid_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 73 .batch(batch_size) 74 .prefetch(buffer_size=tf.data.AUTOTUNE)) 75 return train_dataset, valid_dataset 76 77 78 class CTCLayer(layers.Layer): 79 """CTC loss layer.""" 80 81 def __init__(self, name=None): 82 super().__init__(name=name) 83 self.loss_fn = tf.keras.backend.ctc_batch_cost 84 85 def call(self, y_true, y_pred): 86 # compute the training-time loss value and add it 87 # to the layer using `self.add_loss()`. 88 batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64") 89 input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64") 90 label_length = tf.cast(tf.shape(y_true)[1], dtype="int64") 91 92 input_length = input_length * tf.ones(shape=(batch_len, 1), 93 dtype="int64") 94 label_length = label_length * tf.ones(shape=(batch_len, 1), 95 dtype="int64") 96 97 loss = self.loss_fn(y_true, y_pred, input_length, label_length) 98 self.add_loss(loss) 99 100 # at test time, just return the computed predictions 101 return y_pred 102 103 104 @step(name="data_loading") 105 def load_split_dataset() -> Tuple[MarshalData, MarshalData, MarshalData, 106 MarshalData, MarshalData]: 107 """Load and split dataset.""" 108 # path to the data directory 109 data_dir = Path("./captcha_images_v2/") 110 111 # get list of all the images 112 images = sorted(list(map(str, list(data_dir.glob("*.png"))))) 113 labels = [img.split(os.path.sep)[-1].split(".png")[0] for img in images] 114 characters = sorted(list(set(char for label in labels for char in label))) 115 116 # Splitting data into training and validation sets 117 x_train, x_valid, y_train, y_valid = _split_data(np.array(images), 118 np.array(labels)) 119 return x_train, x_valid, y_train, y_valid, characters 120 121 122 @step(name='model_definition') 123 def build_model(img_width: int, img_height: int, 124 characters: MarshalData) -> MarshalData: 125 # Mapping characters to integers 126 char_to_num = layers.StringLookup(vocabulary=list(characters), 127 mask_token=None) 128 # Inputs to the model 129 inputs = layers.Input(shape=(img_width, img_height, 1), name="image", 130 dtype="float32") 131 132 labels = layers.Input(name="label", shape=(None,), dtype="float32") 133 134 # First conv block 135 x = layers.Conv2D(32, (3, 3), activation="relu", 136 kernel_initializer="he_normal", 137 padding="same", name="Conv1")(inputs) 138 x = layers.MaxPooling2D((2, 2), name="pool1")(x) 139 140 # Second conv block 141 x = layers.Conv2D(64, (3, 3), activation="relu", 142 kernel_initializer="he_normal", 143 padding="same", name="Conv2")(x) 144 x = layers.MaxPooling2D((2, 2), name="pool2")(x) 145 146 # We have used two max pool with pool size and strides 2. 147 # Hence, downsampled feature maps are 4x smaller. The number of 148 # filters in the last layer is 64. Reshape accordingly before 149 # passing the output to the RNN part of the model 150 new_shape = ((img_width // 4), (img_height // 4) * 64) 151 x = layers.Reshape(target_shape=new_shape, name="reshape")(x) 152 x = layers.Dense(64, activation="relu", name="dense1")(x) 153 x = layers.Dropout(0.2)(x) 154 155 # RNNs 156 x = layers.Bidirectional( 157 layers.LSTM(128, return_sequences=True, dropout=0.25))(x) 158 x = layers.Bidirectional( 159 layers.LSTM(64, return_sequences=True, dropout=0.25))(x) 160 161 # Output layer 162 x = layers.Dense(len(char_to_num.get_vocabulary()) + 1, 163 activation="softmax", 164 name="dense2")(x) 165 166 # Add CTC layer for calculating CTC loss at each step 167 output = CTCLayer(name="ctc_loss")(labels, x) 168 169 # Define the model 170 model = tf.keras.Model(inputs=[inputs, labels], 171 outputs=output, 172 name="ocr_model_v1") 173 return model 174 175 176 @step(name="model_training") 177 def train(model: MarshalData, x_train: MarshalData, y_train: MarshalData, 178 x_valid: MarshalData, y_valid: MarshalData, 179 batch_size: int, characters: MarshalData, epochs: int, 180 early_stopping_patience: int) -> MarshalData: 181 """Train a Tensorflow model.""" 182 # Get datasets 183 train_dataset, validation_dataset = _get_preprocessed_datasets(x_train, 184 y_train, 185 x_valid, 186 y_valid, 187 batch_size, 188 characters) 189 # Add early stopping 190 early_stopping = tf.keras.callbacks.EarlyStopping( 191 monitor="val_loss", patience=early_stopping_patience, 192 restore_best_weights=True) 193 194 # Compile the model and return 195 model.compile(optimizer="adam") 196 197 # Train the model 198 model.fit(train_dataset, validation_data=validation_dataset, 199 epochs=epochs, callbacks=[early_stopping]) 200 201 return model 202 203 204 @pipeline(name="tensorflow", experiment="tensorflow-tutorial") 205 def ml_pipeline(img_width: int = 200, img_height: int = 50, 206 batch_size: int = 16, epochs: int = 100, 207 early_stopping_patience: int = 5): 208 """Run the ML pipeline.""" 209 x_train, x_valid, y_train, y_valid, characters = load_split_dataset() 210 model = build_model(img_width, img_height, characters) 211 train(model, x_train, y_train, x_valid, y_valid, 212 batch_size, characters, epochs, early_stopping_patience) 213 214 215 if __name__ == "__main__": 216 ml_pipeline() This script defines a KFP run using the Kale SDK. Specifically, it defines a pipeline with three steps:
- The first step (
data_loading) loads and splits theCAPTCHAdataset. - The second step (
model_definition) defines thetf.keras.Model. - The third step (
model_training) trains the TensorFlow model and displays the loss using aCTC loss layer.
- The first step (
Create a new step function which logs an
TensorflowModelartifact, using the Kale API. The following snippet summarizes the changes in code:Important
Running these pipelines locally won’t work. After introducing
register_modelstep, run the pipeline as a KFP pipeline, since this step creates a Kubeflow artifact.tensorflow_log_model_artifact.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-14 4 5 This script uses an ML pipeline to train and serve an Tensorflow Model. 6 """ 7 8 import os 9 10 import numpy as np 11 import tensorflow as tf 12 13 from pathlib import Path 14 from typing import Tuple 15 16 from tensorflow.keras import layers 17 18 + from kale.ml import Signature 19 from kale.types import MarshalData 20 from kale.sdk import pipeline, step 21 + from kale.common import mlmdutils, artifacts 22 23 24 def _split_data(images, labels, train_size=0.9, shuffle=False): 25-202 25 # get the total size of the dataset 26 size = len(images) 27 # make an indices array and shuffle it, if required 28 indices = np.arange(size) 29 if shuffle: 30 np.random.shuffle(indices) 31 # get the size of training samples 32 train_samples = int(size * train_size) 33 # split data into training and validation sets 34 x_train = images[indices[:train_samples]] 35 y_train = labels[indices[:train_samples]] 36 x_valid = images[indices[train_samples:]] 37 y_valid = labels[indices[train_samples:]] 38 return x_train, x_valid, y_train, y_valid 39 40 41 def _get_preprocessed_datasets(x_train, y_train, x_valid, y_valid, 42 batch_size, characters): 43 44 def _encode_single_sample(img_path, label, img_width=200, img_height=50): 45 # read image 46 img = tf.io.read_file(img_path) 47 # decode and convert to grayscale 48 img = tf.io.decode_png(img, channels=1) 49 # convert to float32 in [0, 1] range 50 img = tf.image.convert_image_dtype(img, tf.float32) 51 # resize to the desired size 52 img = tf.image.resize(img, [img_height, img_width]) 53 # transpose the image because we want the time 54 # dimension to correspond to the width of the image. 55 img = tf.transpose(img, perm=[1, 0, 2]) 56 # map the characters in label to numbers 57 label = char_to_num( 58 tf.strings.unicode_split(label, input_encoding="UTF-8")) 59 # return a dict as our model is expecting two inputs 60 return {"image": img, "label": label} 61 62 # mapping characters to integers 63 char_to_num = layers.StringLookup(vocabulary=list(characters), 64 mask_token=None) 65 66 # Training dataset object 67 train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) 68 train_dataset = (train_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 69 .batch(batch_size) 70 .prefetch(buffer_size=tf.data.AUTOTUNE)) 71 72 # Validation dataset object 73 valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)) 74 valid_dataset = (valid_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 75 .batch(batch_size) 76 .prefetch(buffer_size=tf.data.AUTOTUNE)) 77 return train_dataset, valid_dataset 78 79 80 class CTCLayer(layers.Layer): 81 """CTC loss layer.""" 82 83 def __init__(self, name=None): 84 super().__init__(name=name) 85 self.loss_fn = tf.keras.backend.ctc_batch_cost 86 87 def call(self, y_true, y_pred): 88 # compute the training-time loss value and add it 89 # to the layer using `self.add_loss()`. 90 batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64") 91 input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64") 92 label_length = tf.cast(tf.shape(y_true)[1], dtype="int64") 93 94 input_length = input_length * tf.ones(shape=(batch_len, 1), 95 dtype="int64") 96 label_length = label_length * tf.ones(shape=(batch_len, 1), 97 dtype="int64") 98 99 loss = self.loss_fn(y_true, y_pred, input_length, label_length) 100 self.add_loss(loss) 101 102 # at test time, just return the computed predictions 103 return y_pred 104 105 106 @step(name="data_loading") 107 def load_split_dataset() -> Tuple[MarshalData, MarshalData, MarshalData, 108 MarshalData, MarshalData]: 109 """Load and split dataset.""" 110 # path to the data directory 111 data_dir = Path("./captcha_images_v2/") 112 113 # get list of all the images 114 images = sorted(list(map(str, list(data_dir.glob("*.png"))))) 115 labels = [img.split(os.path.sep)[-1].split(".png")[0] for img in images] 116 characters = sorted(list(set(char for label in labels for char in label))) 117 118 # Splitting data into training and validation sets 119 x_train, x_valid, y_train, y_valid = _split_data(np.array(images), 120 np.array(labels)) 121 return x_train, x_valid, y_train, y_valid, characters 122 123 124 @step(name='model_definition') 125 def build_model(img_width: int, img_height: int, 126 characters: MarshalData) -> MarshalData: 127 # Mapping characters to integers 128 char_to_num = layers.StringLookup(vocabulary=list(characters), 129 mask_token=None) 130 # Inputs to the model 131 inputs = layers.Input(shape=(img_width, img_height, 1), name="image", 132 dtype="float32") 133 134 labels = layers.Input(name="label", shape=(None,), dtype="float32") 135 136 # First conv block 137 x = layers.Conv2D(32, (3, 3), activation="relu", 138 kernel_initializer="he_normal", 139 padding="same", name="Conv1")(inputs) 140 x = layers.MaxPooling2D((2, 2), name="pool1")(x) 141 142 # Second conv block 143 x = layers.Conv2D(64, (3, 3), activation="relu", 144 kernel_initializer="he_normal", 145 padding="same", name="Conv2")(x) 146 x = layers.MaxPooling2D((2, 2), name="pool2")(x) 147 148 # We have used two max pool with pool size and strides 2. 149 # Hence, downsampled feature maps are 4x smaller. The number of 150 # filters in the last layer is 64. Reshape accordingly before 151 # passing the output to the RNN part of the model 152 new_shape = ((img_width // 4), (img_height // 4) * 64) 153 x = layers.Reshape(target_shape=new_shape, name="reshape")(x) 154 x = layers.Dense(64, activation="relu", name="dense1")(x) 155 x = layers.Dropout(0.2)(x) 156 157 # RNNs 158 x = layers.Bidirectional( 159 layers.LSTM(128, return_sequences=True, dropout=0.25))(x) 160 x = layers.Bidirectional( 161 layers.LSTM(64, return_sequences=True, dropout=0.25))(x) 162 163 # Output layer 164 x = layers.Dense(len(char_to_num.get_vocabulary()) + 1, 165 activation="softmax", 166 name="dense2")(x) 167 168 # Add CTC layer for calculating CTC loss at each step 169 output = CTCLayer(name="ctc_loss")(labels, x) 170 171 # Define the model 172 model = tf.keras.Model(inputs=[inputs, labels], 173 outputs=output, 174 name="ocr_model_v1") 175 return model 176 177 178 @step(name="model_training") 179 def train(model: MarshalData, x_train: MarshalData, y_train: MarshalData, 180 x_valid: MarshalData, y_valid: MarshalData, 181 batch_size: int, characters: MarshalData, epochs: int, 182 early_stopping_patience: int) -> MarshalData: 183 """Train a Tensorflow model.""" 184 # Get datasets 185 train_dataset, validation_dataset = _get_preprocessed_datasets(x_train, 186 y_train, 187 x_valid, 188 y_valid, 189 batch_size, 190 characters) 191 # Add early stopping 192 early_stopping = tf.keras.callbacks.EarlyStopping( 193 monitor="val_loss", patience=early_stopping_patience, 194 restore_best_weights=True) 195 196 # Compile the model and return 197 model.compile(optimizer="adam") 198 199 # Train the model 200 model.fit(train_dataset, validation_data=validation_dataset, 201 epochs=epochs, callbacks=[early_stopping]) 202 203 return model 204 205 206 + @step(name="register_model") 207 + def register_model(model: MarshalData) -> int: 208 + mlmd = mlmdutils.get_mlmd_instance() 209 + 210 + signature = Signature( 211 + input_size=[1] + list(model.inputs[0].shape), 212 + output_size=[1] + list(model.outputs[0].shape), 213 + input_dtype=model.inputs[0].dtype, 214 + output_dtype=model.outputs[0].dtype) 215 + 216 + model_artifact = artifacts.TFKerasModel( 217 + model=model, 218 + description="A Tensorflow model", 219 + version="1.0.0", 220 + author="Kale", 221 + signature=signature, 222 + tags={"app": "tensorflow-tutorial"}).submit_artifact() 223 + 224 + mlmd.link_artifact_as_output(model_artifact.id) 225 + return model_artifact.id 226 + 227 + 228 @pipeline(name="tensorflow", experiment="tensorflow-tutorial") 229 def ml_pipeline(img_width: int = 200, img_height: int = 50, 230 batch_size: int = 16, epochs: int = 100, 231 - early_stopping_patience: int = 5): 232 + early_stopping_patience: int = 2): 233 """Run the ML pipeline.""" 234 x_train, x_valid, y_train, y_valid, characters = load_split_dataset() 235 model = build_model(img_width, img_height, characters) 236 - train(model, x_train, y_train, x_valid, y_valid, 237 - batch_size, characters, epochs, early_stopping_patience) 238 + trained_model = train(model, x_train, y_train, x_valid, y_valid, 239 + batch_size, characters, epochs, 240 + early_stopping_patience) 241 + register_model(trained_model) 242 243 244 if __name__ == "__main__": 245 ml_pipeline() Create a new step function which serves the
TFKerasModelartifact you logged in the previous step, using the KaleserveAPI:tensorflow_serve.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-14 4 5 This script uses an ML pipeline to train and serve an Tensorflow Model. 6 """ 7 8 import os 9 10 import numpy as np 11 import tensorflow as tf 12 13 from pathlib import Path 14 from typing import Tuple 15 16 from tensorflow.keras import layers 17 18 + from kale.serve import serve 19 from kale.ml import Signature 20 from kale.types import MarshalData 21 from kale.sdk import pipeline, step 22-225 22 from kale.common import mlmdutils, artifacts 23 24 25 def _split_data(images, labels, train_size=0.9, shuffle=False): 26 # get the total size of the dataset 27 size = len(images) 28 # make an indices array and shuffle it, if required 29 indices = np.arange(size) 30 if shuffle: 31 np.random.shuffle(indices) 32 # get the size of training samples 33 train_samples = int(size * train_size) 34 # split data into training and validation sets 35 x_train = images[indices[:train_samples]] 36 y_train = labels[indices[:train_samples]] 37 x_valid = images[indices[train_samples:]] 38 y_valid = labels[indices[train_samples:]] 39 return x_train, x_valid, y_train, y_valid 40 41 42 def _get_preprocessed_datasets(x_train, y_train, x_valid, y_valid, 43 batch_size, characters): 44 45 def _encode_single_sample(img_path, label, img_width=200, img_height=50): 46 # read image 47 img = tf.io.read_file(img_path) 48 # decode and convert to grayscale 49 img = tf.io.decode_png(img, channels=1) 50 # convert to float32 in [0, 1] range 51 img = tf.image.convert_image_dtype(img, tf.float32) 52 # resize to the desired size 53 img = tf.image.resize(img, [img_height, img_width]) 54 # transpose the image because we want the time 55 # dimension to correspond to the width of the image. 56 img = tf.transpose(img, perm=[1, 0, 2]) 57 # map the characters in label to numbers 58 label = char_to_num( 59 tf.strings.unicode_split(label, input_encoding="UTF-8")) 60 # return a dict as our model is expecting two inputs 61 return {"image": img, "label": label} 62 63 # mapping characters to integers 64 char_to_num = layers.StringLookup(vocabulary=list(characters), 65 mask_token=None) 66 67 # Training dataset object 68 train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) 69 train_dataset = (train_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 70 .batch(batch_size) 71 .prefetch(buffer_size=tf.data.AUTOTUNE)) 72 73 # Validation dataset object 74 valid_dataset = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)) 75 valid_dataset = (valid_dataset.map(_encode_single_sample, tf.data.AUTOTUNE) 76 .batch(batch_size) 77 .prefetch(buffer_size=tf.data.AUTOTUNE)) 78 return train_dataset, valid_dataset 79 80 81 class CTCLayer(layers.Layer): 82 """CTC loss layer.""" 83 84 def __init__(self, name=None): 85 super().__init__(name=name) 86 self.loss_fn = tf.keras.backend.ctc_batch_cost 87 88 def call(self, y_true, y_pred): 89 # compute the training-time loss value and add it 90 # to the layer using `self.add_loss()`. 91 batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64") 92 input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64") 93 label_length = tf.cast(tf.shape(y_true)[1], dtype="int64") 94 95 input_length = input_length * tf.ones(shape=(batch_len, 1), 96 dtype="int64") 97 label_length = label_length * tf.ones(shape=(batch_len, 1), 98 dtype="int64") 99 100 loss = self.loss_fn(y_true, y_pred, input_length, label_length) 101 self.add_loss(loss) 102 103 # at test time, just return the computed predictions 104 return y_pred 105 106 107 @step(name="data_loading") 108 def load_split_dataset() -> Tuple[MarshalData, MarshalData, MarshalData, 109 MarshalData, MarshalData]: 110 """Load and split dataset.""" 111 # path to the data directory 112 data_dir = Path("./captcha_images_v2/") 113 114 # get list of all the images 115 images = sorted(list(map(str, list(data_dir.glob("*.png"))))) 116 labels = [img.split(os.path.sep)[-1].split(".png")[0] for img in images] 117 characters = sorted(list(set(char for label in labels for char in label))) 118 119 # Splitting data into training and validation sets 120 x_train, x_valid, y_train, y_valid = _split_data(np.array(images), 121 np.array(labels)) 122 return x_train, x_valid, y_train, y_valid, characters 123 124 125 @step(name='model_definition') 126 def build_model(img_width: int, img_height: int, 127 characters: MarshalData) -> MarshalData: 128 # Mapping characters to integers 129 char_to_num = layers.StringLookup(vocabulary=list(characters), 130 mask_token=None) 131 # Inputs to the model 132 inputs = layers.Input(shape=(img_width, img_height, 1), name="image", 133 dtype="float32") 134 135 labels = layers.Input(name="label", shape=(None,), dtype="float32") 136 137 # First conv block 138 x = layers.Conv2D(32, (3, 3), activation="relu", 139 kernel_initializer="he_normal", 140 padding="same", name="Conv1")(inputs) 141 x = layers.MaxPooling2D((2, 2), name="pool1")(x) 142 143 # Second conv block 144 x = layers.Conv2D(64, (3, 3), activation="relu", 145 kernel_initializer="he_normal", 146 padding="same", name="Conv2")(x) 147 x = layers.MaxPooling2D((2, 2), name="pool2")(x) 148 149 # We have used two max pool with pool size and strides 2. 150 # Hence, downsampled feature maps are 4x smaller. The number of 151 # filters in the last layer is 64. Reshape accordingly before 152 # passing the output to the RNN part of the model 153 new_shape = ((img_width // 4), (img_height // 4) * 64) 154 x = layers.Reshape(target_shape=new_shape, name="reshape")(x) 155 x = layers.Dense(64, activation="relu", name="dense1")(x) 156 x = layers.Dropout(0.2)(x) 157 158 # RNNs 159 x = layers.Bidirectional( 160 layers.LSTM(128, return_sequences=True, dropout=0.25))(x) 161 x = layers.Bidirectional( 162 layers.LSTM(64, return_sequences=True, dropout=0.25))(x) 163 164 # Output layer 165 x = layers.Dense(len(char_to_num.get_vocabulary()) + 1, 166 activation="softmax", 167 name="dense2")(x) 168 169 # Add CTC layer for calculating CTC loss at each step 170 output = CTCLayer(name="ctc_loss")(labels, x) 171 172 # Define the model 173 model = tf.keras.Model(inputs=[inputs, labels], 174 outputs=output, 175 name="ocr_model_v1") 176 return model 177 178 179 @step(name="model_training") 180 def train(model: MarshalData, x_train: MarshalData, y_train: MarshalData, 181 x_valid: MarshalData, y_valid: MarshalData, 182 batch_size: int, characters: MarshalData, epochs: int, 183 early_stopping_patience: int) -> MarshalData: 184 """Train a Tensorflow model.""" 185 # Get datasets 186 train_dataset, validation_dataset = _get_preprocessed_datasets(x_train, 187 y_train, 188 x_valid, 189 y_valid, 190 batch_size, 191 characters) 192 # Add early stopping 193 early_stopping = tf.keras.callbacks.EarlyStopping( 194 monitor="val_loss", patience=early_stopping_patience, 195 restore_best_weights=True) 196 197 # Compile the model and return 198 model.compile(optimizer="adam") 199 200 # Train the model 201 model.fit(train_dataset, validation_data=validation_dataset, 202 epochs=epochs, callbacks=[early_stopping]) 203 204 return model 205 206 207 @step(name="register_model") 208 def register_model(model: MarshalData) -> int: 209 mlmd = mlmdutils.get_mlmd_instance() 210 211 signature = Signature( 212 input_size=[1] + list(model.inputs[0].shape), 213 output_size=[1] + list(model.outputs[0].shape), 214 input_dtype=model.inputs[0].dtype, 215 output_dtype=model.outputs[0].dtype) 216 217 model_artifact = artifacts.TFKerasModel( 218 model=model, 219 description="A Tensorflow model", 220 version="1.0.0", 221 author="Kale", 222 signature=signature, 223 tags={"app": "tensorflow-tutorial"}).submit_artifact() 224 225 mlmd.link_artifact_as_output(model_artifact.id) 226 return model_artifact.id 227 228 229 + @step(name="serve_model") 230 + def serve_model(model_artifact_id: int): 231 + serve_config = {"limits": {"memory": "4Gi"}, 232 + "annotations": {"sidecar.istio.io/inject": "false"}} 233 + serve(name="tensorflow-tutorial", 234 + model_id=model_artifact_id, 235 + serve_config=serve_config) 236 + 237 + 238 @pipeline(name="tensorflow", experiment="tensorflow-tutorial") 239 def ml_pipeline(img_width: int = 200, img_height: int = 50, 240 batch_size: int = 16, epochs: int = 100, 241-244 241 early_stopping_patience: int = 2): 242 """Run the ML pipeline.""" 243 x_train, x_valid, y_train, y_valid, characters = load_split_dataset() 244 model = build_model(img_width, img_height, characters) 245 trained_model = train(model, x_train, y_train, x_valid, y_valid, 246 batch_size, characters, epochs, 247 early_stopping_patience) 248 - register_model(trained_model) 249 + model_artifact_id = register_model(trained_model) 250 + serve_model(model_artifact_id) 251 252 253 if __name__ == "__main__": 254 ml_pipeline() Deploy and run your code as a KFP pipeline:
$ python3 -m kale serve_tensorflow_model.py --kfpNote
This example does not produce a good performing model for the CAPTCHA dataset. It is just a starting point to build a pipeline and experiment rapidly. If you have added a GPU device and you want to create a more accurate model, increase the
early_stopping_patiencepipeline parameter from5to50. Theearly_stopping_patienceparameter sets the number of epochs to wait for improvement before stopping the training.When the
register_modelstep completes, you can view the model artifact through the KFP UI: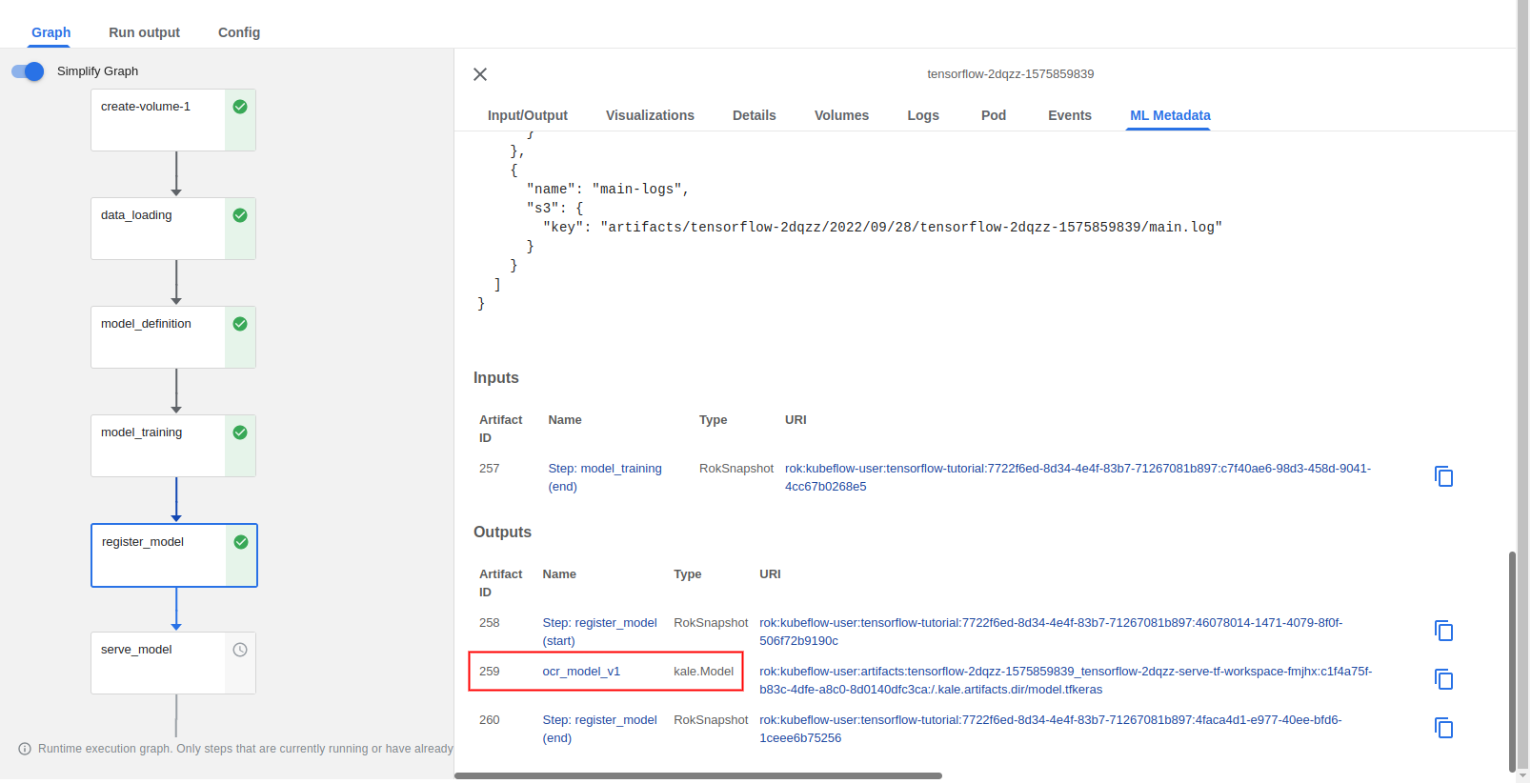
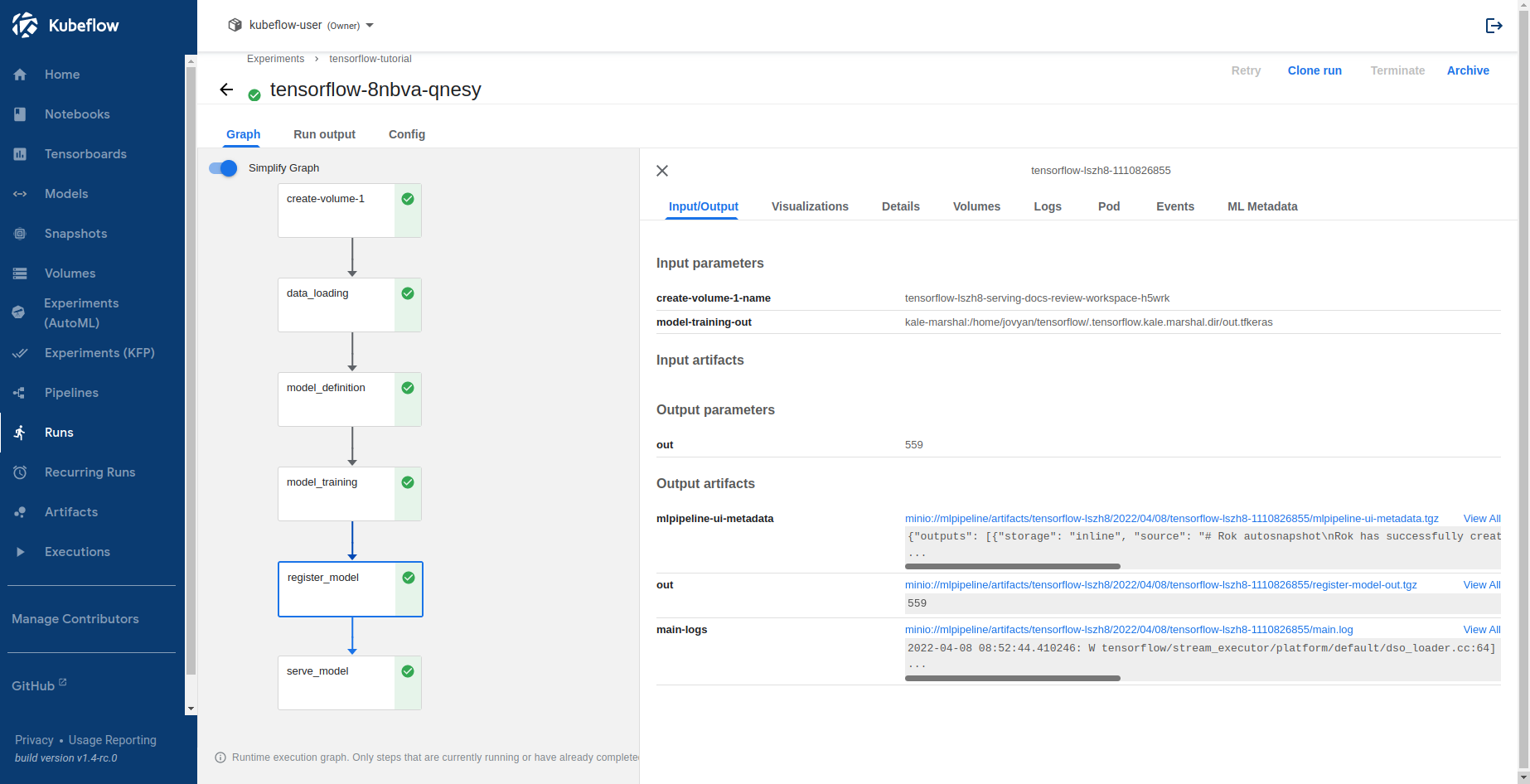
Select Runs to view the KFP run you just created. This is what it looks like when the pipeline completes successfully:
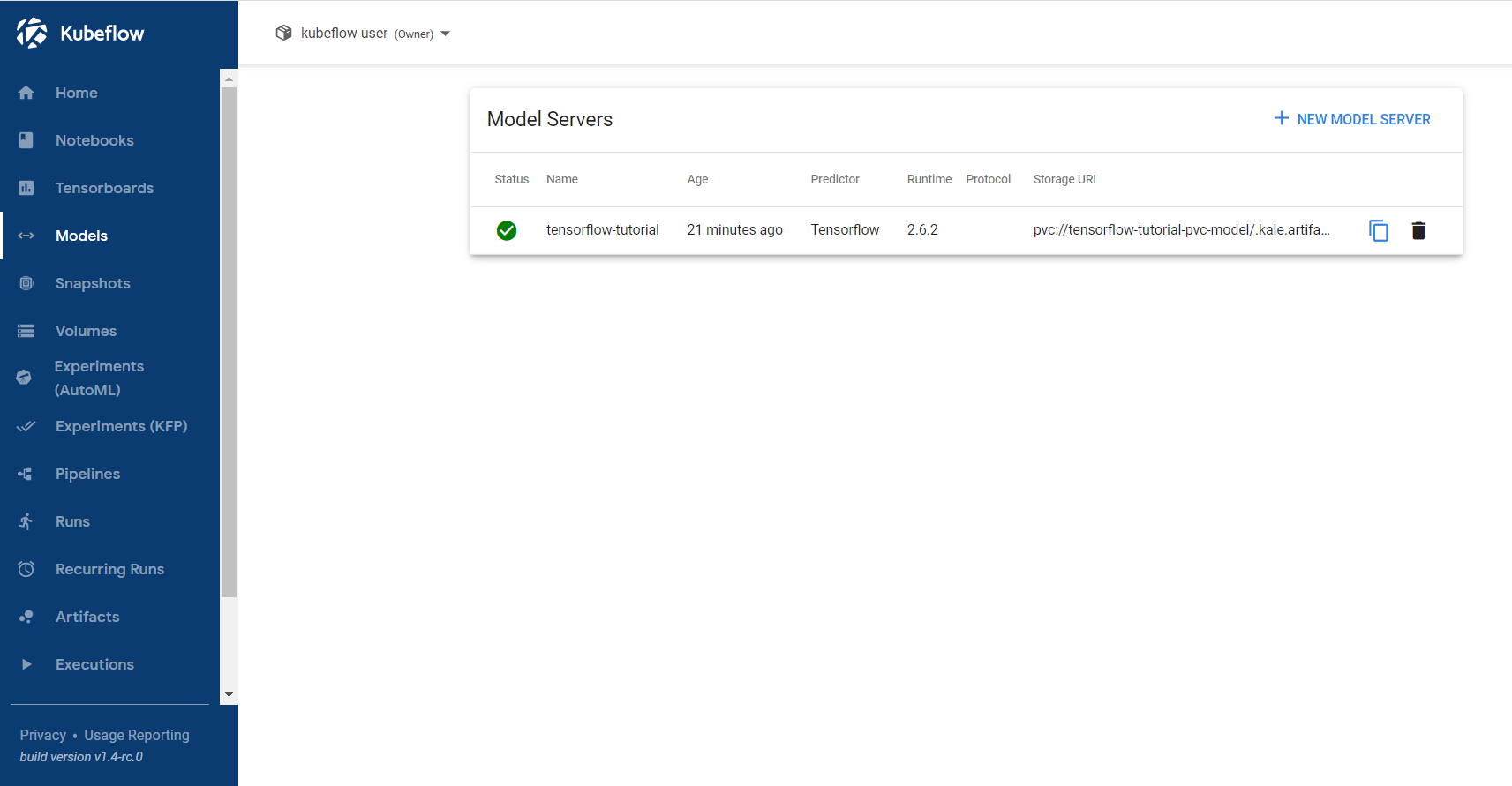
Select Models and click on the endpoint you created:
Get Predictions¶
In this section, you will query the model endpoint to get predictions for the images from the validation subset.
Navigate to the Models UI and retrieve the name of the
InferenceService. In this example, it istensorflow-tutorial.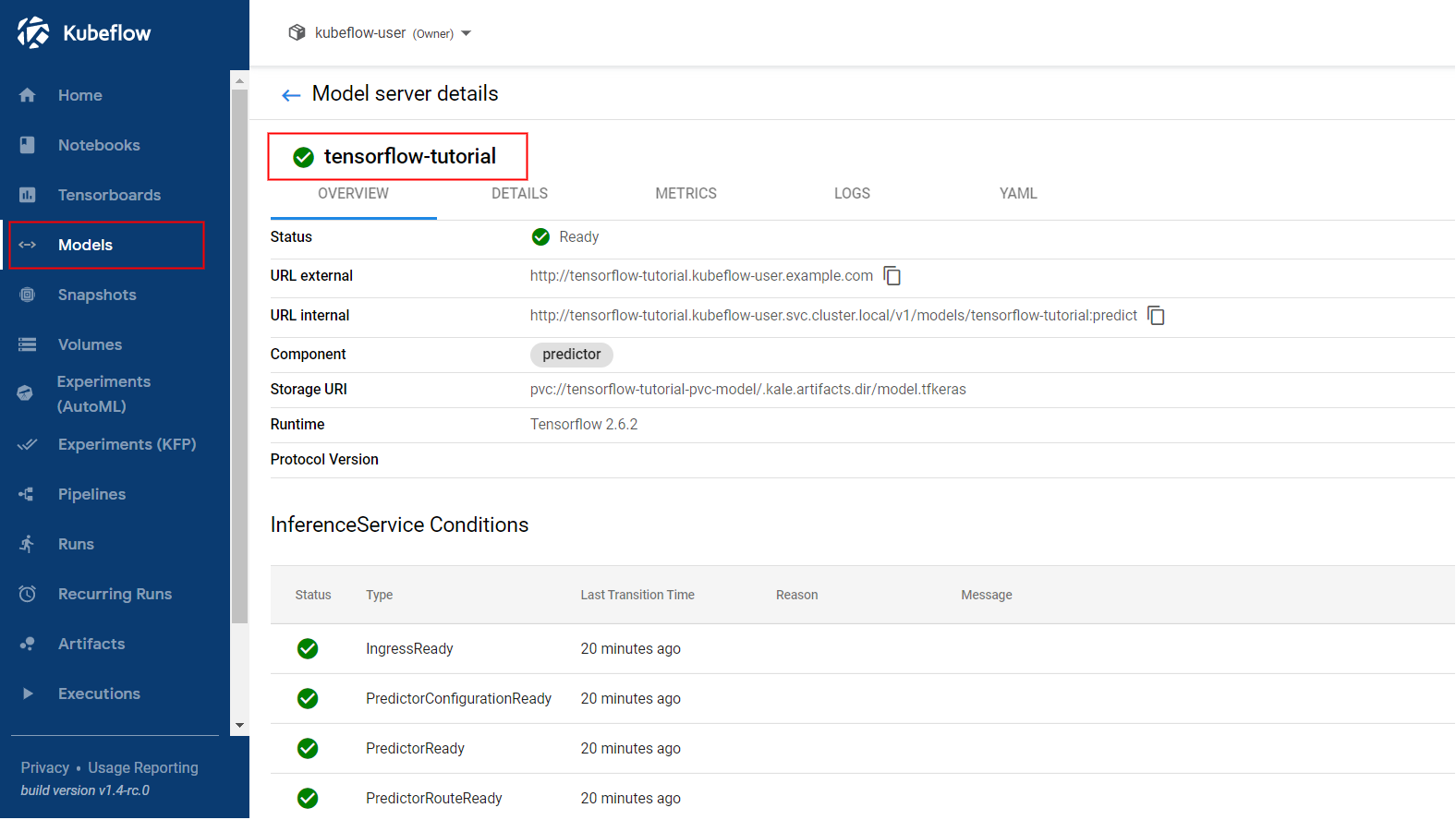
In the existing notebook, in a different code cell, initialize a Kale
Endpointobject using the name of theInferenceServiceyou retrieved in the previous step. Then, run the cell:Note
When initializing an
Endpoint, you can also pass the namespace of theInferenceService. For example, if your namespace ismy-namespace:If you do not provide one, Kale assumes the namespace of the notebook server. In our case, it is
kubeflow-user.This is how your notebook cell will look like:

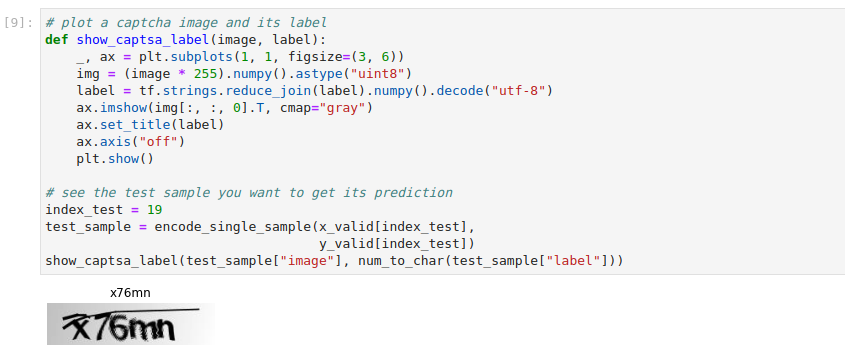
Visualize the test sample you will use to hit the model endpoint. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:
Convert the test example into JSON format. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:

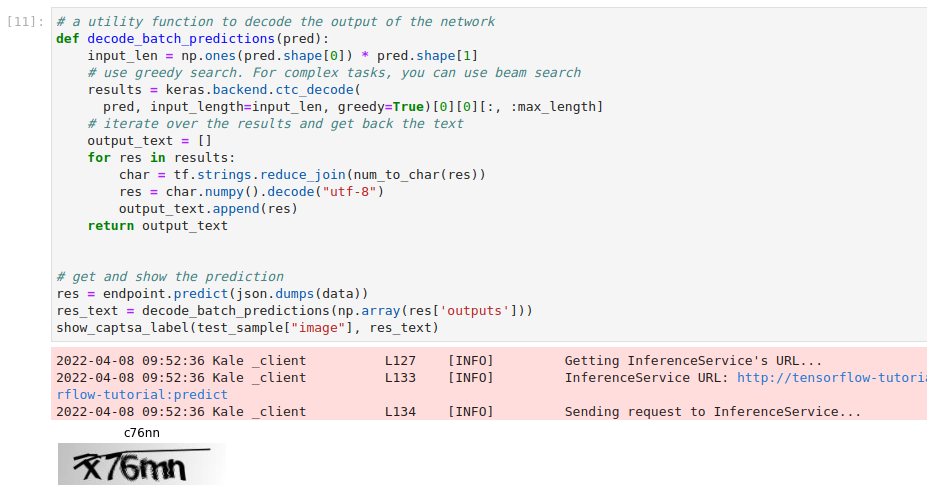
Invoke the server to get predictions. Copy and paste the following snippet in a different code cell, and run it:
This is how your notebook cell will look like: