
Arrikto Enterprise Kubeflow Components and Features¶
The Arrikto Enterprise Kubeflow (EKF) distribution extends the capabilities of the OSS Kubeflow platform with additional automation, reproducibility, portability, and security features. As we describe the components of Arrikto EKF and their features below, we’ll identify the gaps each feature works to fill.
Kale¶
The Kale Arrikto EKF component simplifies the use of Kubeflow, giving data scientists the tools they need to orchestrate end-to-end ML workflows for themselves. Kale provides both an SDK and a UI in the form of a JupyterLab extension. The SDK can be used to orchestrate workflows from any repository of Python code. The aim of the Kale SDK is to allow you to write plain Python code and then be able to convert it to fully reproducible Kubeflow pipelines without making any change to the original source code. The JupyterLab extension provides a convenient UI for workflow orchestration from within Jupyter Notebooks.
Kale enables you to
- Iterate on ML code without creating new Docker images.
- Deploy reproducible ML pipelines directly from your code.
- Configure and launch hyperparmeter tuning jobs.
- Configure and launch AutoML jobs to run experiments and select the best performing model.
- Serve models for use by applications.
Iterate on ML Code without Creating New Docker Images¶
The OSS Kubeflow pipelines platform enables you to define complex workflows in production environments. However, using this platform requires a level of engineering expertise beyond that of most data scientists. OSS Kubeflow requires you to containerize all pipeline components, typically this means that ML Engineers must refactor data scientist’s original code for production. OSS Kubeflow also requires you to define pipelines using the platform’s domain-specific language (DSL). Kale overcomes these obstacles with an experience designed to support data scientists.
Kale enables data scientists to experiment fast and iteratively as they are accustomed to doing in an IDE such as a Jupyter Notebook. Data scientists can then easily orchestrate their workflow using the power and scalability of Kubernetes when ready to do so.
Note
This aspect of Kale helps address automation gaps in OSS Kubeflow.
Deploy Pipelines Directly from Your Code¶
Kale automates creating Kubeflow pipelines, enabling users to move from rapidly prototyping their models to creating reusable and scalable pipelines easily. Jupyter Notebook users can simply label cells in a notebook to identify pipeline steps. Those using other IDEs can use Python decorators provided by the Kale SDK to identify the functions that implement steps of a pipeline.
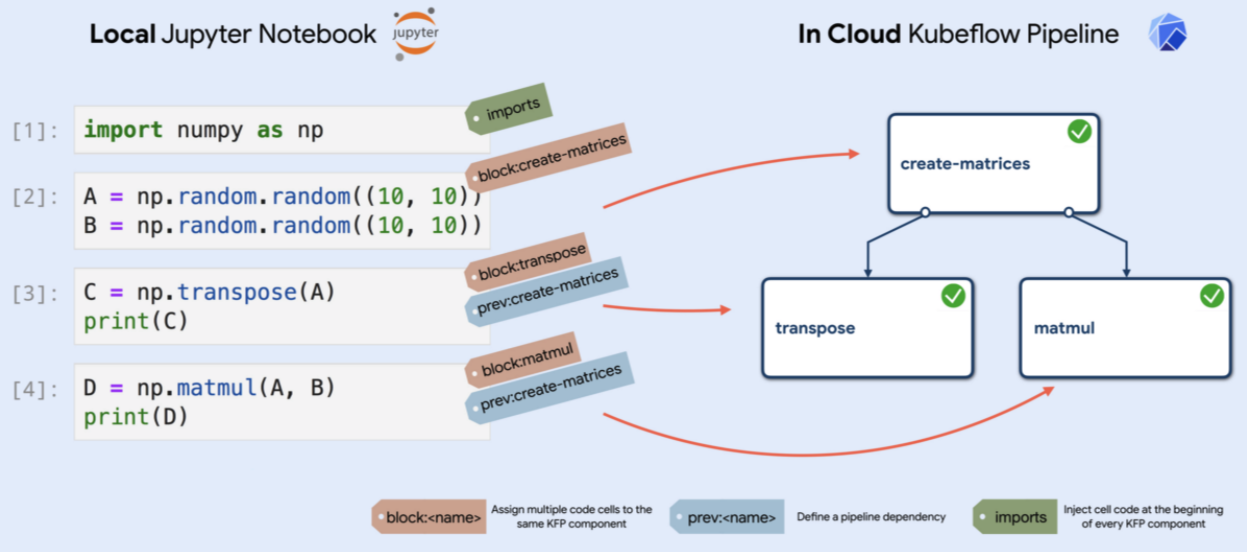
Based on the annotations you supply, Kale
- Assigns code to specific pipeline components.
- Defines the (execution) dependencies between them.
- Defines the pipeline using lightweight components in the Kubeflow pipelines SDK.
Kale ensures that all the processing building blocks are well organized and independent from each other, while also leveraging on the experiment tracking and workflows organization provided out-of-the-box by OSS Kubeflow.
Note
The ability to deploy pipelines directly from your code helps address automation gaps in OSS Kubeflow.
Run Pipelines from Your IDE¶
Kale simplifies running pipelines by providing the ability to launch pipelines directly from the Jupyter Notebooks IDE. Once run, you can view your run as a graph and run experiments to compare the results of different pipeline runs as usual in Kubeflow.
Note
This Arrikto EKF feature helps address automation gaps in OSS Kubeflow.
Kale Automatically Manages Dependencies¶
Kale makes sure that all the newly installed libraries will find their way into pipeline runs. Kale uses the Arrikto EFK Rok component, described below, to implement dependency management. Normally, you should create a new Docker image to be able to run your code as a Kubeflow pipeline, to include newly installed libraries. Fortunately, Rok and Kale make sure that any libraries you install during development will find their way to your pipeline, thanks to Rok’s snapshotting technology and Kale mounting those snapshotted volumes into the pipeline steps.
As a user, you simply iterate on your Python code as usual, importing libraries, declaring variables, creating objects, etc. To ensure that each independent pipeline step has access to the data and other dependencies it requires, Kale runs a series of static analyses over the source Python code to detect where variables and objects are first declared and then used. In this way, Kale creates an internal graph representation describing the data dependencies between the pipeline steps.
Kubeflow pipeline components are necessarily independent to facilitate efficient resource usage and scaling. To enable you to share dependencies from one component to another, Kale uses the dependency graph to determine what objects must be serialized and shared between components. Kale does all this automatically for you by injecting code at the beginning and end of each component to marshal objects into a shared Kubernetes Persistent Volume Claim (PVC) during execution.
Note
Dependency management in Arrikto EKF helps address automation gaps in OSS Kubeflow.
Snapshot and Reproduce Pipelines and Steps¶
One of the most valuable features of Kale is that it snapshots each run of a pipeline and, more importantly, the start and end of the execution of each pipeline component. Kale uses Rok (see below for an overview) to handle data versioning. Rok snapshots your whole pipeline execution environment when you run a pipeline using Kale.
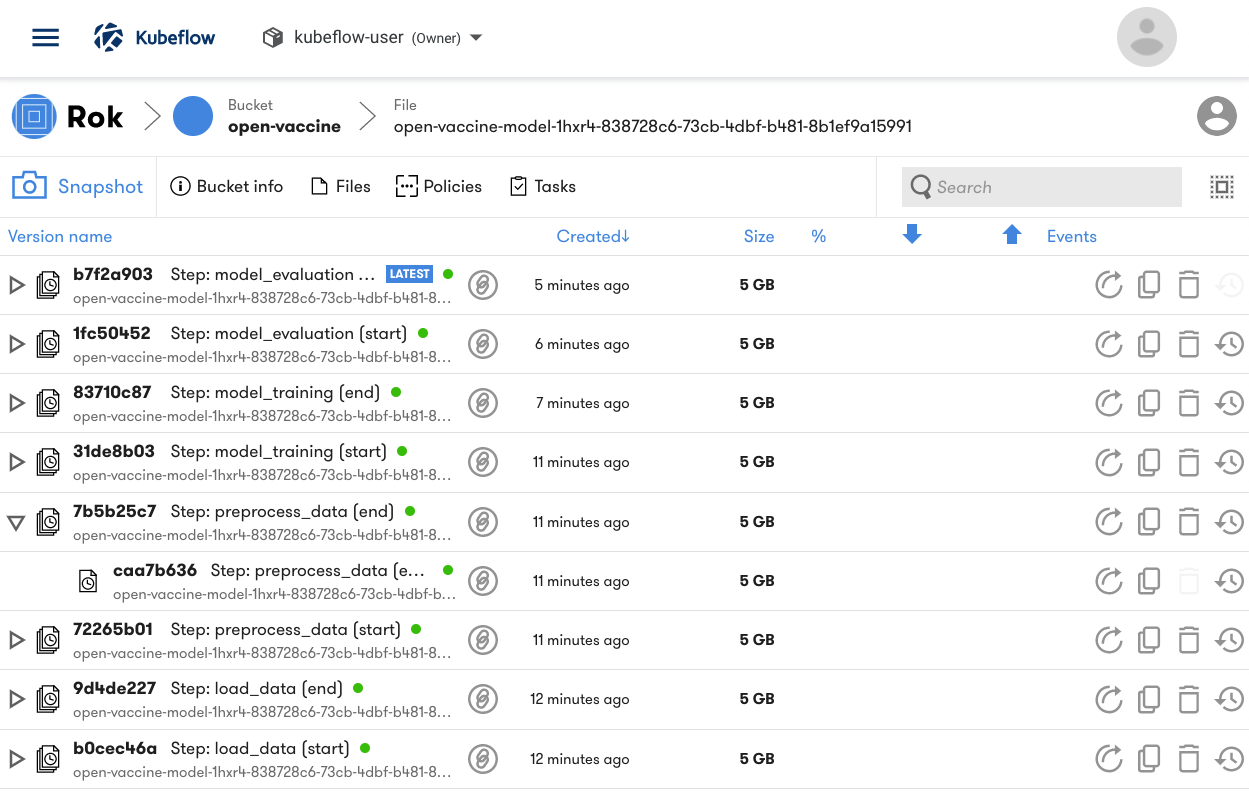
So, rather than needing to re-run an entire pipeline, you can simply re-run from the point in the pipeline just before the step in which you make changes. This enables data scientists to iterate on any step of a pipeline without having to incur the time and compute costs of re-running all the prior steps.
The Arrikto EKF UI for Jupyter enables you to launch a notebook server using a Rok snapshot for complete reproducibility. Publication/subscription functionality provided by the Rok Registry component of Enterprise Kubeflow enables data scientists to share snapshots with and use snapshots created by other users. The snapshot management UI enables you to manage sharing, snapshot retention and other policies.
Note
Snapshotting pipelines helps address reproducibility gaps in OSS Kubeflow.
Tune Hyperparameters¶
Kale enables you to optimize models using hyperparameter tuning. Kale uses Katib, Kubeflow’s hyperparameter tuning component, for these jobs. Kale will orchestrate Katib and Kubeflow pipeline experiments so that every Katib trial is a pipeline run in Kubeflow Pipelines.
Katib is Kubeflow’s component to run general purpose hyperparameter tuning jobs. Katib does not know anything about the jobs that it is actually running (called trials in Katib jargon). All that it cares about is the search space, the optimization algorithm, and the goal. Katib supports running simple jobs as trials, but Kale implements a shim to have the trials run pipelines in Kubeflow Pipelines and then collect the metrics from the pipeline runs.
To set up hyperparameter tuning you annotate a block of code as the parameters to tune and another block as the pipeline metrics to test as outcomes of an experiment. Finally, you configure the search space parameters, run parameters and define a search algorithm and search objective.
The JupyterLab UI provides panels that enable you to easily set up and run hyperparameter tuning experiments using Katib. The SDK enables hyperparameter tuning via parameterized Python decorators.
Note
Kale’s hyperparameter tuning capabilities help address automation gaps in OSS Kubeflow.
Serve Models¶
Serving models via the KServe component in OSS Kubeflow requires learning the KServe SDK and likely requires intervention from ML engineers. With Kale on Enterprise Kubeflow, data scientists can serve models by running a simple command using the Kale SDK. Kale recognizes the type of the model, dumps it locally, then takes a Rok snapshot and creates an inference service via KServe.
Enterprise Kubeflow also provides a UI to expose the entire state of KServe. In this UI, you can monitor all the inference services that you deploy and review metrics and logs for each service.
Note
Model serving in Arrikto EKF helps address automation gaps in OSS Kubeflow.
Rok¶
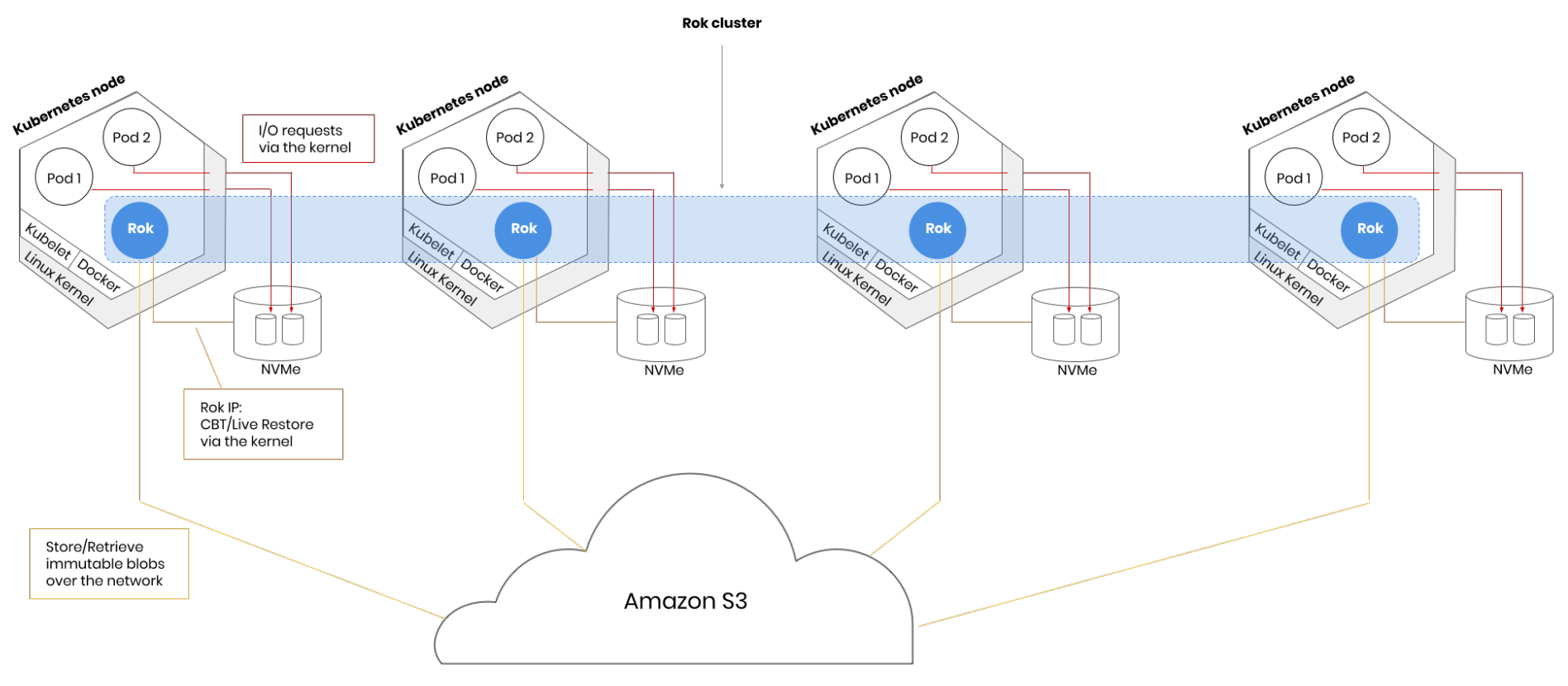
Rok provides a data management layer for Kubeflow that provisions Persistent Volume Claims (PVCs) on pods in a way that enables directly-attached, local NVMe devices to become primary, persistent storage. Rok is a generic storage and data management solution that provides a StorageClass for Kubernetes and integrates at the Kubernetes level via the Container Storage Interface (CSI). It is a standalone solution that can be used independently from Kubeflow. However, Rok is distributed with Enterprise Kubeflow and provides services that support a number of Enterprise Kubeflow features.
Run Pipelines on High Performance NVMe Devices¶
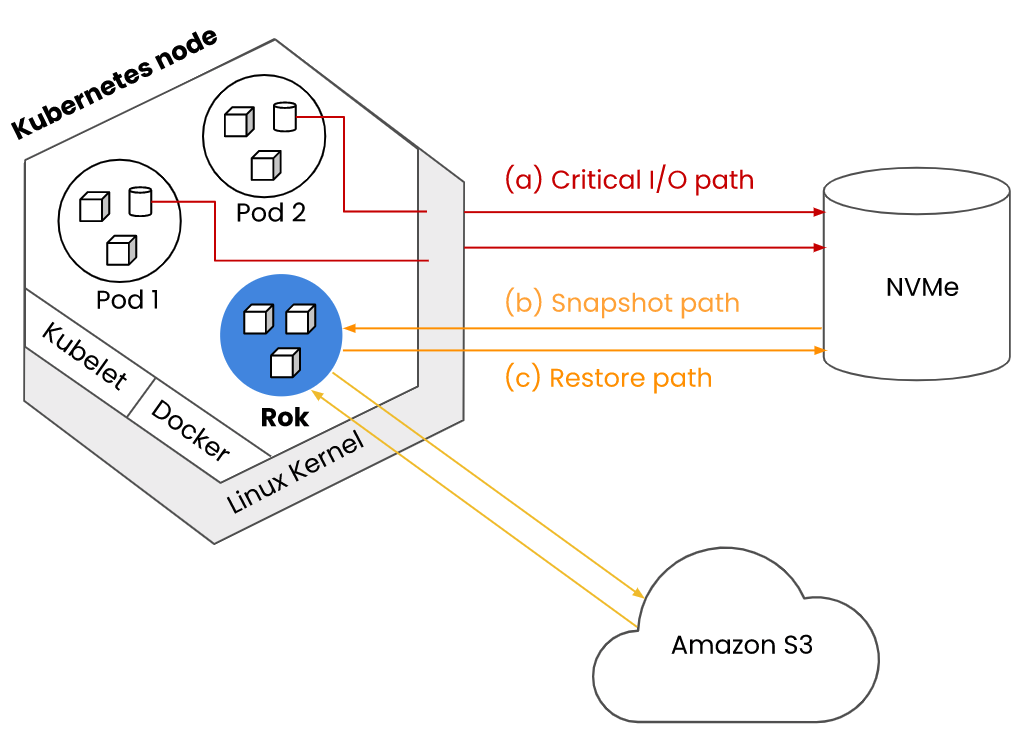
Rok integrates via the Kubernetes Container Storage Interface (CSI). It is in the critical control path of provisioning and managing volumes; however, it is not in the critical path of I/O. All I/O flows directly via the Linux kernel. Rok uses mainline kernel utilities to provision what eventually will be a kernel block device provided to the pod. This is fast, because all I/O requests issued by the pod will enter the Linux kernel, get processed by kernel code only, and will eventually get served by the NVMe device, which is directly-attached to the same physical host.
Note
This is different from what any other container storage, traditional software-defined storage (SDS), or cloud vendor’s block/file solution will do, where requests are processed by vendor code and have to go through the network before they complete.
View and Manage Files in PVCs¶
Arrikto EKF via Rok enables you to manage files inside PVCs using a convenient file manager UI. Using the file manager, you can browse, upload, download, and delete files a volume contains. This includes files created by services attached to the volume such as those created within a Jupyter Notebooks environment. The EKF file manager UI requires no Kubernetes knowledge. It is ideally suited for data scientists and anyone else who needs to manage files in your clusters.
Note
File management capabilities in Arrikto EFK feature helps address automation gaps in OSS Kubeflow.
See the EKF file manager video tour for a brief walkthrough of this feature (1:58).
Package Your Environment with Snapshots¶
Rok enables you to create snapshots of local persistent volumes. In Arrikto EKF, this includes volumes containing ML pipeline code and data, JupyterLab environments, datasets, models, and other artifacts or data in your deployment. Taking snapshots does not impact application performance, because it happens outside the application I/O path using Arrikto’s Linux kernel enhancements, which are now part of mainline Linux.
Rok hashes, de-duplicates, and versions snapshots and then stores the de-duplicated, content-addressable parts on an Object Storage service (e.g., Amazon S3) that is close to the specific Kubernetes cluster.
Note
The ability to package your environment in Arrikto EKF helps address reproducibility gaps in OSS Kubeflow.
See the packaging video tour for a brief walkthrough of this feature (0:30).
Version your Environment¶
An important value that Rok snapshots provide is in the ability to version entire environments much in the same way that you can version code with Git. Rok snapshots enable you to iterate on your environment as you transform datasets, develop models, and develop other aspects of an ML workflow.
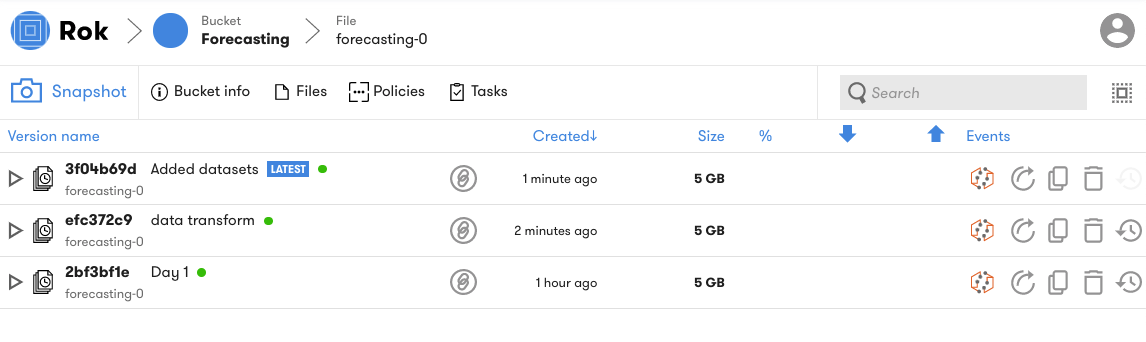
Note
Arrikto EKF’s versioning feature helps address automation and reproducibility gaps in OSS Kubeflow.
See the versioning video tour for a brief walkthrough of this feature (0:18).
Schedule Snapshots and Define Retention Policies¶
You may define a variety of policies on volume snapshots using Rok. These include the following:
- The schedule on which snapshots are taken and which resources in a volume should be included in a snapshot.
- Retention policies.
- Policies on sharing snapshots.
Note
Scheduled snapshots help address automation and reproducibility gaps in OSS Kubeflow.
Create New Volumes from Snapshots¶
Rok enables restoring snapshots on new local volumes on any other node of the cluster. This enables you to recreate a complete environment exactly the way it was at any point in time. Rok provides two options during restoration, both of which are transparent for the application and Kubernetes:
- Rok restores the volume immediately and hydrates the live volume in the background while the app is reading and writing. After the local volume is hydrated, Rok uses Linux kernel mechanisms to remove itself from the critical I/O path live and transparently to the app.
- Rok hydrates first and then provides the volume for use. This option supports apps that are sensitive to latency. In this case Rok never gets into the critical I/O path.
Note
The ability to create new volumes from snapshots helps address reproducibility and portability gaps in OSS Kubeflow.
Rok Registry¶
Rok Registry enables you to search, discover, and share snapshots with other users. You can create private or public groups on Rok Registry and can define fine-grained access control lists (ACLs).
Rok Registry connects multiple Kubernetes clusters running Rok into a decentralized network, in a federated fashion. The clusters may reside on-prem, on different cloud providers, or different regions of the same cloud provider. Rok Registry stores only references to data, not the actual data, and allows Rok instances to sync snapshots between them by exchanging content-addressable snapshot pieces over the P2P network. Eventually, when users create new snapshots, only the changed parts have to traverse the network.
Rok Registry gets deployed via a Kubernetes Operator, and runs as a deployment on one of the Kubernetes clusters. Rok Registry is not in the critical path of data syncing. If it goes down, the worst thing that will happen is that users won’t be able to create new ACLs until Rok Registry comes back up.
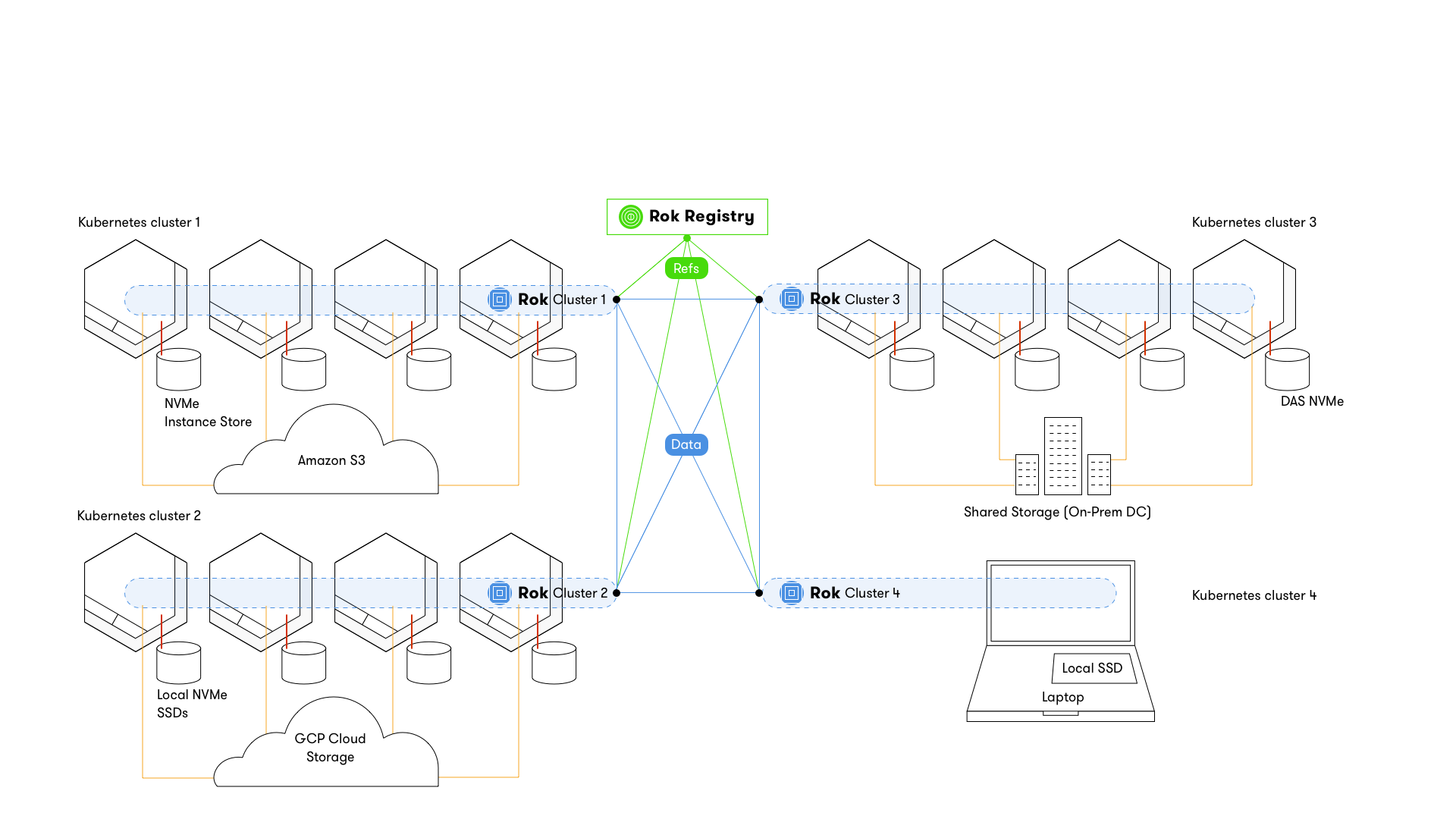
Rok Registry is to Rok what GitHub is to Git, but decentralized. Rok uses a publish/subscribe model to enable users to share and collaborate across clusters, including clusters running on local environments. Rok Registry enables users to publish buckets containing snapshots of their environment and make them discoverable by other users. Other users with appropriate authorization can subscribe to published buckets. Rok ensures that changes made by a publisher are synced to all those subscribed to the corresponding bucket. Rok captures each published change as a discrete version, enabling you to restore prior versions easily.
Using Rok Registry users can share snapshots of datasets, ML pipelines, and entire Jupyter Notebook server environments.
Note
Rok Registry helps address portability and security gaps in OSS Kubeflow.
See the sharing, syncing, and distribution video tours for a brief walkthrough of these features (2:08).