Serving Runtimes¶
A Serving Runtime is a template for defining serving backends for specific Machine Learning frameworks. Each Serving Runtime captures key information such as the container image of the runtime and a list of the ML frameworks that it supports.
Note
For more information about the serving runtimes, see the KServe Serving Runtimes documentation.
In this guide you will learn how to write and submit a ServingRuntime CR to define a custom serving backend.
What You’ll Need¶
- An Arrikto EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how the Kale SDK works.
- An understanding of how the Kale serve API works.
Procedure¶
This guide comprises two sections: In the first section, you will learn what a ServingRuntime CR is, create a custom one, and use it to serve a Scikit Learn classifier. Then, in the second section, you will invoke the InferenceService you created during the first step to get back the predictions.
Serve the model¶
In this section, you will create a custom ServingRuntime CR and use Kale to serve a Scikit Learn classifier leveraging this backend.
Create a new notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or Arrikto EKF release.Connect to the notebook server, open a terminal, and create a new YAML file to define your ServingRuntime:
$ touch sklearn-runtime.yamlOpen the YAML file and add the following content:
apiVersion: serving.kserve.io/v1alpha1 kind: ServingRuntime metadata: name: user-sklearnserver spec: containers: - args: - --model_name={{.Name}} - --model_dir=/mnt/models - --http_port=8080 image: kserve/sklearnserver:v0.7.0 name: kserve-container resources: limits: cpu: "1" memory: 2Gi requests: cpu: "1" memory: 2Gi supportedModelFormats: - name: sklearn version: "2"Here, you create a ServingRuntime that uses the
kserve/sklearnserverimage to serve Scikit Learn models. The ServingRuntime explicitely says that is supports the Scikit Learn framework in thesupportedModelFormatssection and it is versioned. This is useful when you want to support multiple versions of the same framework. It also contains other information such as the container image arguments and the resource limits that will be applied to every model served with this runtime.Save the file and submit it to the Kubernetes cluster:
$ kubectl apply -f sklearn-runtime.yamlIn the same notebook server, open a terminal, create a new Python file, and name it
serve_sklearn_model.py:$ touch serve_sklearn_model.pyCopy and paste the following code inside
serve_sklearn_model.py:sklearn_runtime.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script uses an ML pipeline to train and serve an SKLearn Model. 6 """ 7 8 from typing import Tuple, NamedTuple 9 10 from sklearn.feature_extraction import text 11 from sklearn.naive_bayes import MultinomialNB 12 from sklearn.datasets import fetch_20newsgroups 13 from sklearn.model_selection import train_test_split 14 from sklearn.feature_extraction.text import TfidfVectorizer 15 16 from kale.serve import serve 17 from kale.ml import Signature 18 from kale.types import MarshalData 19 from kale.sdk import pipeline, step 20 from kale.common import mlmdutils, artifacts 21 22 23 @step(name="data_loading") 24 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 25 """Fetch 20newgroup dataset.""" 26 # load the data 27 newsgroups_dataset = fetch_20newsgroups(random_state=42) 28 x = newsgroups_dataset.data 29 y = newsgroups_dataset.target 30 x, _, y, _ = train_test_split(x, y, test_size=.2, random_state=42) 31 32 return x, y 33 34 35 @step(name="data_preprocess") 36 def preprocess(x: MarshalData) -> MarshalData: 37 """Preprocess the input data.""" 38 # get stopwords 39 stop_words = text.ENGLISH_STOP_WORDS 40 # TF-IDF vectors 41 vectorizer = TfidfVectorizer(stop_words=stop_words) 42 x_processed = vectorizer.fit_transform(x) 43 44 return x_processed 45 46 47 @step(name="model_training") 48 def train(x: MarshalData, 49 y: MarshalData) -> NamedTuple("outs", [("model", MarshalData)]): 50 """Train a MultinomialNB model.""" 51 classifier = MultinomialNB(alpha=.01) 52 model = classifier.fit(x, y) 53 return model 54 55 56 @step(name="register_model") 57 def register_model(model: MarshalData, x: MarshalData, y: MarshalData) -> int: 58 mlmd = mlmdutils.get_mlmd_instance() 59 60 signature = Signature( 61 input_size=[1] + list(x[0].shape), 62 output_size=[1] + list(y[0].shape), 63 input_dtype=x.dtype, 64 output_dtype=y.dtype) 65 66 model_artifact = artifacts.SklearnModel( 67 model=model, 68 description="A simple MultinomialNB model", 69 version="1.0.0", 70 author="Kale", 71 signature=signature, 72 tags={"app": "sklearn-tutorial"}).submit_artifact() 73 74 mlmd.link_artifact_as_output(model_artifact.id) 75 return model_artifact.id 76 77 78 @step(name="serve_model") 79 def serve_model(model_artifact_id: int): 80 serve(name="sklearn-tutorial", model_id=model_artifact_id) 81 82 83 @pipeline(name="classification", experiment="sklearn-tutorial") 84 def ml_pipeline(): 85 """Run the ML pipeline.""" 86 x, y = load_split_dataset() 87 x_processed = preprocess(x) 88 model = train(x_processed, y) 89 artifact_id = register_model(model, x_processed, y) 90 serve_model(artifact_id) 91 92 93 if __name__ == "__main__": 94 ml_pipeline() Instruct KServe to use the custom runtime you created in the earlier step:
sklearn_runtime_serve.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-76 4 5 This script uses an ML pipeline to train and serve an SKLearn Model. 6 """ 7 8 from typing import Tuple, NamedTuple 9 10 from sklearn.feature_extraction import text 11 from sklearn.naive_bayes import MultinomialNB 12 from sklearn.datasets import fetch_20newsgroups 13 from sklearn.model_selection import train_test_split 14 from sklearn.feature_extraction.text import TfidfVectorizer 15 16 from kale.serve import serve 17 from kale.ml import Signature 18 from kale.types import MarshalData 19 from kale.sdk import pipeline, step 20 from kale.common import mlmdutils, artifacts 21 22 23 @step(name="data_loading") 24 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 25 """Fetch 20newgroup dataset.""" 26 # load the data 27 newsgroups_dataset = fetch_20newsgroups(random_state=42) 28 x = newsgroups_dataset.data 29 y = newsgroups_dataset.target 30 x, _, y, _ = train_test_split(x, y, test_size=.2, random_state=42) 31 32 return x, y 33 34 35 @step(name="data_preprocess") 36 def preprocess(x: MarshalData) -> MarshalData: 37 """Preprocess the input data.""" 38 # get stopwords 39 stop_words = text.ENGLISH_STOP_WORDS 40 # TF-IDF vectors 41 vectorizer = TfidfVectorizer(stop_words=stop_words) 42 x_processed = vectorizer.fit_transform(x) 43 44 return x_processed 45 46 47 @step(name="model_training") 48 def train(x: MarshalData, 49 y: MarshalData) -> NamedTuple("outs", [("model", MarshalData)]): 50 """Train a MultinomialNB model.""" 51 classifier = MultinomialNB(alpha=.01) 52 model = classifier.fit(x, y) 53 return model 54 55 56 @step(name="register_model") 57 def register_model(model: MarshalData, x: MarshalData, y: MarshalData) -> int: 58 mlmd = mlmdutils.get_mlmd_instance() 59 60 signature = Signature( 61 input_size=[1] + list(x[0].shape), 62 output_size=[1] + list(y[0].shape), 63 input_dtype=x.dtype, 64 output_dtype=y.dtype) 65 66 model_artifact = artifacts.SklearnModel( 67 model=model, 68 description="A simple MultinomialNB model", 69 version="1.0.0", 70 author="Kale", 71 signature=signature, 72 tags={"app": "sklearn-tutorial"}).submit_artifact() 73 74 mlmd.link_artifact_as_output(model_artifact.id) 75 return model_artifact.id 76 77 78 @step(name="serve_model") 79 def serve_model(model_artifact_id: int): 80 - serve(name="sklearn-tutorial", model_id=model_artifact_id) 81 + serve_config = {"predictor": {"model_format": {"name": "sklearn", 82 + "version": "2"}, 83 + "runtime": "user-sklearnserver"}} 84 + serve(name="sklearn-tutorial", model_id=model_artifact_id, 85 + serve_config=serve_config) 86 87 88 @pipeline(name="classification", experiment="sklearn-tutorial") 89-96 89 def ml_pipeline(): 90 """Run the ML pipeline.""" 91 x, y = load_split_dataset() 92 x_processed = preprocess(x) 93 model = train(x_processed, y) 94 artifact_id = register_model(model, x_processed, y) 95 serve_model(artifact_id) 96 97 98 if __name__ == "__main__": 99 ml_pipeline() Pay close attention to the properties you pass to the
servefunction, via theserve_configdictionary. Theruntimeproperty is the name of the ServingRuntime you created in the earlier step. Themodel_formatproperty specifies the name of the supported framework, as well as the version of the runtime you’d like to use.Deploy and run your code as a KFP pipeline:
$ python3 -m kale serve_sklearn_model.py --kfp
Get Predictions¶
In this section, you will query the model endpoint to get predictions using a test subset.
Navigate to the Models UI to retrieve the name of the
InferenceService. In this example, it issklearn-tutorial.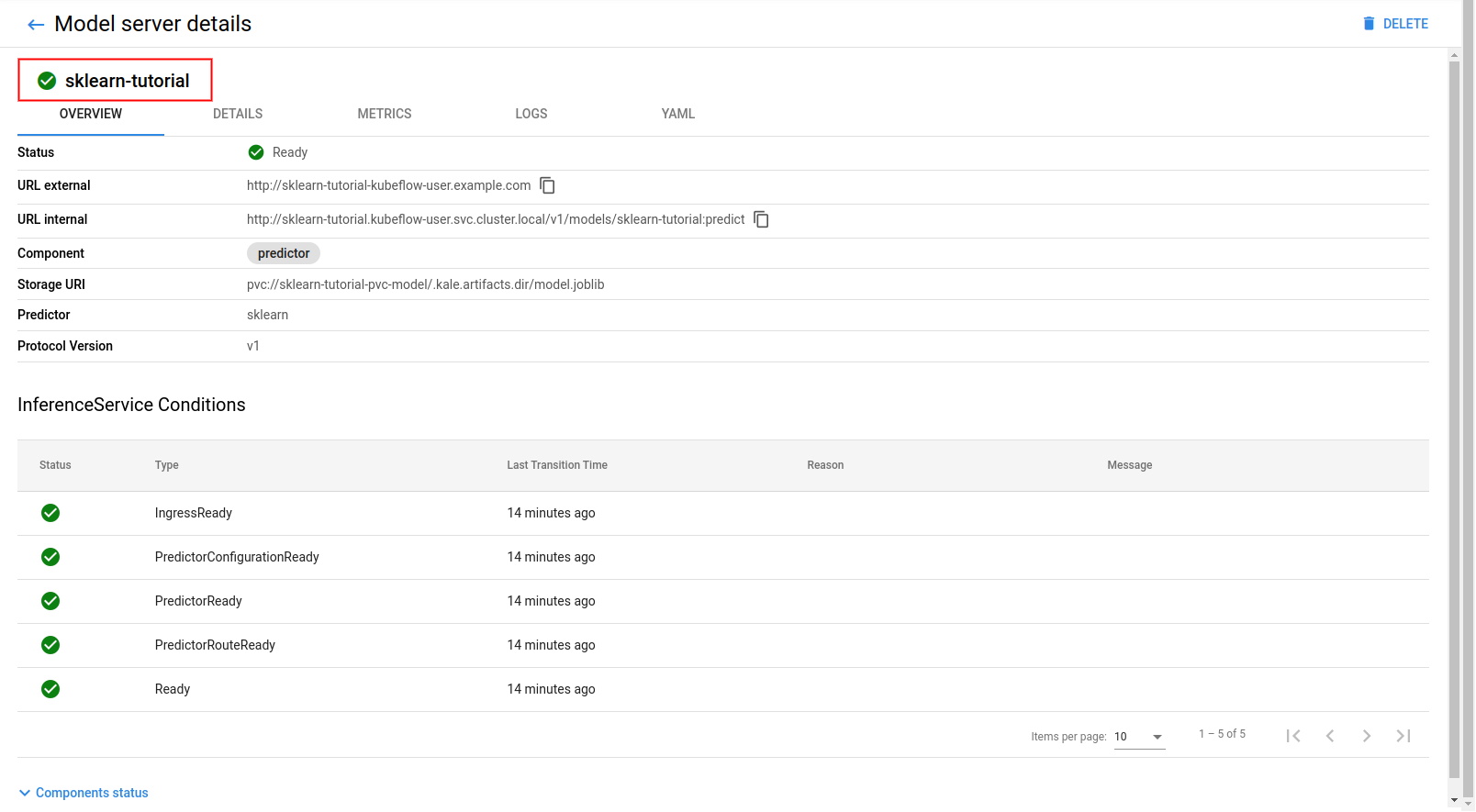
Return to your Notebook server and create a new Jupyter notebook (that is, an IPYNB file):

Copy and paste the import statements in the first code cell, and run it:
This is how your notebook cell will look like:

In a different code cell, fetch the dataset and split it into train and test subsets. Copy and paste the following code, and run it:
This is how your notebook cell will look like:

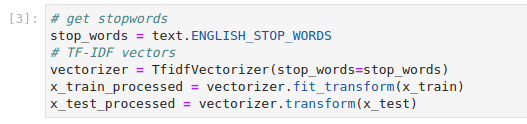
In a different code cell, transform the data using a
TfidfVectorizer. Copy and paste the following code, and run it:This is how your notebook cell will look like:
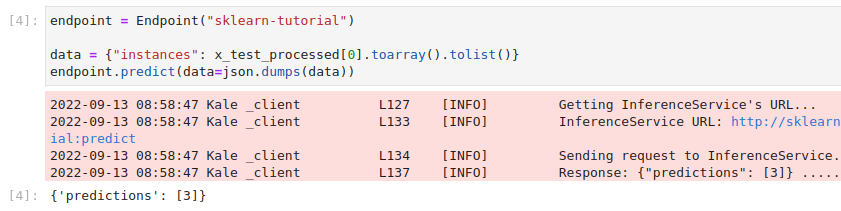
In a different code cell, create an
Endpointobject and invoke the InferenceService endpoint. Copy and paste the following code, and run it:This is how your notebook cell will look like: