
HP Tuning with the Kale JupyterLab Extension¶
This section will guide you through configuring and running a Katib experiment using the Kale JupyterLab extension.
Overview
What You’ll Need¶
- An EKF of MiniKF deployment with the default Kale Docker image.
Procedure¶
Create a new Notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or EKF release.Connect to the server, open a terminal, and install
scikit-learn:$ pip3 install --user scikit-learn==0.23.0Create a new Jupyter Notebook (that is, an IPYNB file) and enable the Kale extension from the left-side panel.
Copy and paste the import statements on the top code cell. Tag the cell with the Kale
Importslabel:This is how your notebook cell will look like:

Copy and paste the following code snippet to a new code cell. Tag the cell with the Kale
Pipeline Parameterslabel:This is how your notebook cell will look like:

Copy and paste the following code snippet to a new code cell. Tag the cell with the Kale
Pipeline Steplabel and name itload_data:This is how your notebook cell will look like:

Copy and paste the following code snippet to a new code cell. Tag the cell with the Kale
Pipeline Steplabel and name itprocess_data. Set the previous step (that is,load_data) as a dependency:This is how your notebook cell will look like:

Copy and paste the following code snippet to a new code cell. Tag the cell with the Kale
Pipeline Steplabel and name ittrain. Set the previous step (that is,process_data) as a dependency:This is how your notebook cell will look like:

Copy and paste the following code snippet to a new code cell. Tag the cell with the Kale
Pipeline Steplabel and name itevaluate. Set the previous step (that is,train) as a dependency:This is how your notebook cell will look like:

Print the pipeline’s metric in the last cell of the Notebook. Tag the cell with the Kale
pipeline-metricslabel:This is how your notebook cell will look like:

Important
You should print the metric you care about in the last code cell of your Notebook.
Enable the
HP Tuning with Katiboption by pressing the corresponding toggle in the Kale extension’s left-side panel: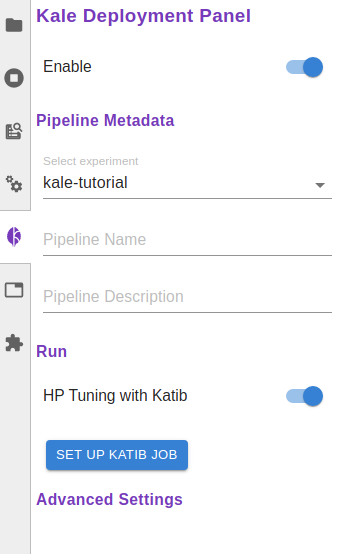
Chose the
SET UP KATIB JOBbutton and use the graphical user interface of the extension to configure the experiment: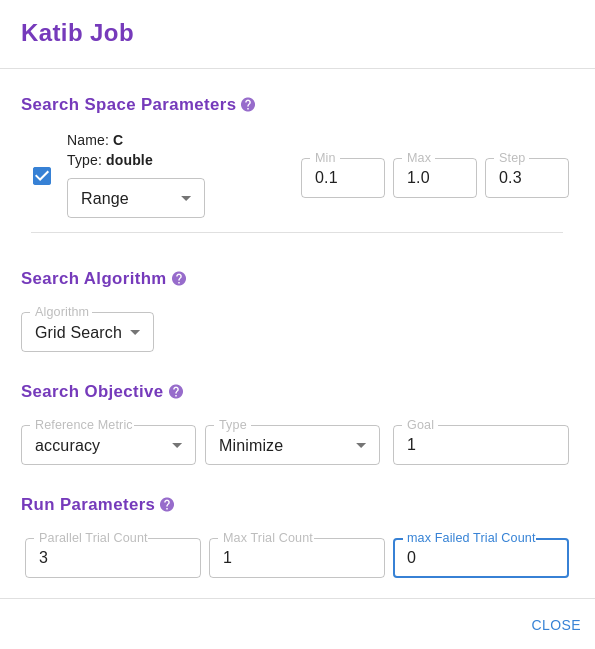
Press the
COMPILE AND RUN KATIB JOBbutton located at the bottom of the extension’s left-side panel.