
Serve LightGBM Models¶
This section will guide you through serving a LightGBM model, using the Kale
serve API.
Overview
What You’ll Need¶
- An Arrikto EKF or MiniKF deployment with the default Kale Docker image.
- An understanding of how the Kale SDK works.
- An understanding of how the Kale serve API works.
Procedure¶
This guide comprises three sections: In the first section, you will explore and process the dataset. Then, in the second section, you will leverage the Kale SDK to build a Machine Learning (ML) pipeline that trains and serves a LightGBM model. Finally, in the third section, you will invoke the model service to get predictions on a holdout test subset.
Load & Split the Dataset¶
In this guide, you will work with the Iris
dataset. The Iris dataset contains information on 3 types of the Iris
plant. It provides 50 instances of each type and the end goal is to predict the
type of the Iris plant for each example.
Create a new notebook server using the default Kale Docker image. The image will have the following naming scheme:
gcr.io/arrikto/jupyter-kale-py38:<IMAGE_TAG>Note
The
<IMAGE_TAG>varies based on the MiniKF or Arrikto EKF release.Connect to the Jupyter server and create a new Jupyter notebook (that is, an IPYNB file):

Install the
lightgbmlibrary in the first code cell:This is how your notebook cell will look like:

Restart the notebook’s kernel using the corresponding button in the UI:

Copy and paste the import statements in the next code cell, and run it:
This is how your notebook cell will look like:
Load the features and targets of the dataset. Copy and paste the following code into a new code cell, and run it:
This is how your notebook cell will look like:
Split the dataset into training and test subsets. In a new cell, copy and paste the following code, and run it:
This is how your notebook cell will look like:

Serve LightGBM Model¶
In the same notebook server, open a terminal, and create a new Python file. Name it
serve_lightgbm_model.py:$ touch serve_lightgbm_model.pyCopy and paste the following code inside
serve_lightgbm_model.py:lightgbm_starter.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4 5 This script uses an ML pipeline to train and serve an LightGBM Model. 6 """ 7 8 import lightgbm as lgb 9 10 from typing import Tuple 11 12 from sklearn.model_selection import train_test_split 13 from sklearn.datasets import load_iris 14 15 from kale.types import MarshalData 16 from kale.sdk import pipeline, step 17 18 19 @step(name="data_loading") 20 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 21 """Fetch Iris dataset.""" 22 # get data and target of the dataset 23 iris = load_iris() 24 x = iris.data 25 y = iris.target 26 27 # split the dataset 28 x_train, _, y_train, _ = train_test_split(x, y, test_size=.2, 29 random_state=42) 30 return x_train, y_train 31 32 33 @step(name="model_training") 34 def train(x: MarshalData, y: MarshalData): 35 """Train a Booster model.""" 36 lgb_train = lgb.Dataset(x, y) 37 38 params = {"objective": "multiclass", 39 "metric": "softmax", 40 "num_class": 3} 41 42 lgb.train(params=params, train_set=lgb_train) 43 44 45 @pipeline(name="regression", experiment="lightgbm-tutorial") 46 def ml_pipeline(): 47 """Run the ML pipeline.""" 48 x_train, y_train = load_split_dataset() 49 train(x_train, y_train) 50 51 52 if __name__ == "__main__": 53 ml_pipeline() This script defines a KFP run using the Kale SDK. Specifically, it defines a pipeline with two steps:
- The first step (
data_loading) loads and splits theIrisdataset. - The second step (
model_training) trains a LightGBMBoostermodel.
- The first step (
Create a new step function which logs an
LightGBMModelartifact, using the Kale API. The following snippet summarizes the changes in code:Important
Running these pipelines locally won’t work. After introducing
register_modelstep, run the pipeline as a KFP pipeline, since this step creates a Kubeflow artifact.lightgbm_log_model_artifact.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-11 4 5 This script uses an ML pipeline to train and serve an LightGBM Model. 6 """ 7 8 import lightgbm as lgb 9 10 from typing import Tuple 11 12 from sklearn.model_selection import train_test_split 13 from sklearn.datasets import load_iris 14 15 + from kale.ml import Signature 16 from kale.types import MarshalData 17 from kale.sdk import pipeline, step 18 + from kale.common import mlmdutils, artifacts 19 20 21 @step(name="data_loading") 22-32 22 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 23 """Fetch Iris dataset.""" 24 # get data and target of the dataset 25 iris = load_iris() 26 x = iris.data 27 y = iris.target 28 29 # split the dataset 30 x_train, _, y_train, _ = train_test_split(x, y, test_size=.2, 31 random_state=42) 32 return x_train, y_train 33 34 35 @step(name="model_training") 36 - def train(x: MarshalData, y: MarshalData): 37 + def train(x: MarshalData, y: MarshalData) -> MarshalData: 38 """Train a Booster model.""" 39 lgb_train = lgb.Dataset(x, y) 40 41-41 41 params = {"objective": "multiclass", 42 "metric": "softmax", 43 "num_class": 3} 44 45 - lgb.train(params=params, train_set=lgb_train) 46 + model = lgb.train(params=params, train_set=lgb_train) 47 + 48 + return model 49 + 50 + 51 + @step(name="register_model") 52 + def register_model(model: MarshalData, x: MarshalData, y: MarshalData): 53 + """Register the model in the MLMD store.""" 54 + mlmd = mlmdutils.get_mlmd_instance() 55 + 56 + signature = Signature( 57 + input_size=[1] + list(x[0].shape), 58 + output_size=[1] + list(y[0].shape), 59 + input_dtype=x.dtype, 60 + output_dtype=y.dtype) 61 + 62 + model_artifact = artifacts.LightGBMModel( 63 + model=model, 64 + description="A simple LightGBM classifier", 65 + version="1.0.0", 66 + author="Kale", 67 + signature=signature, 68 + tags={"app": "lightgbm-tutorial"}).submit_artifact() 69 + 70 + mlmd.link_artifact_as_output(model_artifact.id) 71 72 73 @pipeline(name="regression", experiment="lightgbm-tutorial") 74 def ml_pipeline(): 75 """Run the ML pipeline.""" 76 x_train, y_train = load_split_dataset() 77 - train(x_train, y_train) 78 + model = train(x_train, y_train) 79 + register_model(model, x_train, y_train) 80 81 82 if __name__ == "__main__": 83 ml_pipeline() Create a new step function which serves the
LightGBMModelartifact you created in the previous step, using the KaleserveAPI. The following snippet summarizes the changes in code:lightgbm_serve.py
1 # Copyright © 2022 Arrikto Inc. All Rights Reserved. 2 3 """Kale SDK. 4-11 4 5 This script uses an ML pipeline to train and serve an LightGBM Model. 6 """ 7 8 import lightgbm as lgb 9 10 from typing import Tuple 11 12 from sklearn.model_selection import train_test_split 13 from sklearn.datasets import load_iris 14 15 + from kale.serve import serve 16 from kale.ml import Signature 17 from kale.types import MarshalData 18 from kale.sdk import pipeline, step 19-47 19 from kale.common import mlmdutils, artifacts 20 21 22 @step(name="data_loading") 23 def load_split_dataset() -> Tuple[MarshalData, MarshalData]: 24 """Fetch Iris dataset.""" 25 # get data and target of the dataset 26 iris = load_iris() 27 x = iris.data 28 y = iris.target 29 30 # split the dataset 31 x_train, _, y_train, _ = train_test_split(x, y, test_size=.2, 32 random_state=42) 33 return x_train, y_train 34 35 36 @step(name="model_training") 37 def train(x: MarshalData, y: MarshalData) -> MarshalData: 38 """Train a Booster model.""" 39 lgb_train = lgb.Dataset(x, y) 40 41 params = {"objective": "multiclass", 42 "metric": "softmax", 43 "num_class": 3} 44 45 model = lgb.train(params=params, train_set=lgb_train) 46 47 return model 48 49 50 @step(name="register_model") 51 - def register_model(model: MarshalData, x: MarshalData, y: MarshalData): 52 + def register_model(model: MarshalData, x: MarshalData, y: MarshalData) -> int: 53 """Register the model in the MLMD store.""" 54 mlmd = mlmdutils.get_mlmd_instance() 55 56-67 56 signature = Signature( 57 input_size=[1] + list(x[0].shape), 58 output_size=[1] + list(y[0].shape), 59 input_dtype=x.dtype, 60 output_dtype=y.dtype) 61 62 model_artifact = artifacts.LightGBMModel( 63 model=model, 64 description="A simple LightGBM classifier", 65 version="1.0.0", 66 author="Kale", 67 signature=signature, 68 tags={"app": "lightgbm-tutorial"}).submit_artifact() 69 70 mlmd.link_artifact_as_output(model_artifact.id) 71 + return model_artifact.id 72 + 73 + 74 + @step(name="serve_model") 75 + def serve_model(model_id: int): 76 + serve(name="lightgbm-tutorial", model_id=model_id) 77 78 79 @pipeline(name="regression", experiment="lightgbm-tutorial") 80-80 80 def ml_pipeline(): 81 """Run the ML pipeline.""" 82 x_train, y_train = load_split_dataset() 83 model = train(x_train, y_train) 84 - register_model(model, x_train, y_train) 85 + model_id = register_model(model, x_train, y_train) 86 + serve_model(model_id) 87 88 89 if __name__ == "__main__": 90 ml_pipeline() Deploy and run your code as a KFP pipeline:
$ python3 -m kale serve_lightgbm_model.py --kfpSelect Runs to view the KFP run you just created. This is what it looks like when the pipeline completes successfully:
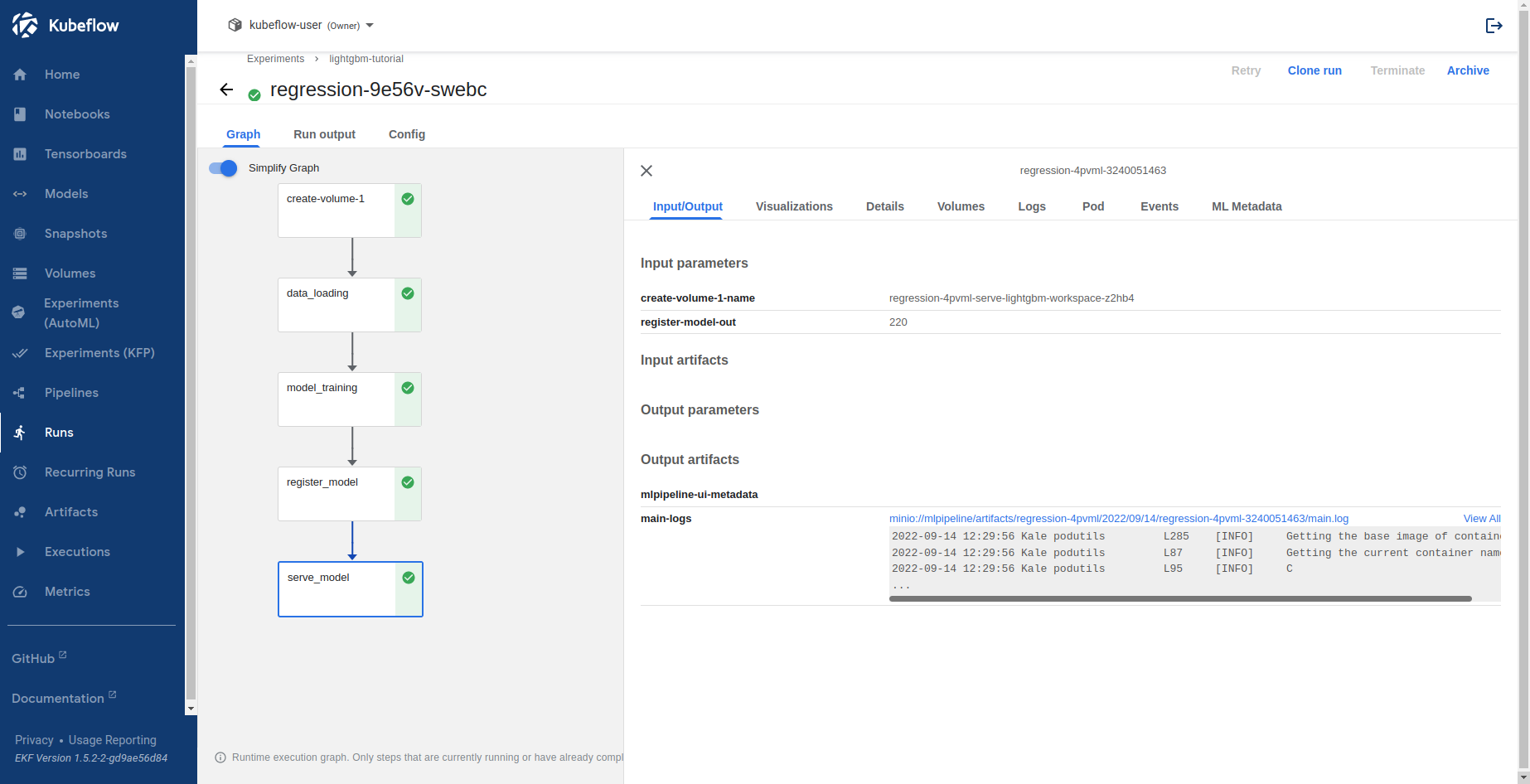
Wait until the pipeline completes. Check the Logs tab of the
serve_modelstep to see whether theInferenceServiceis running.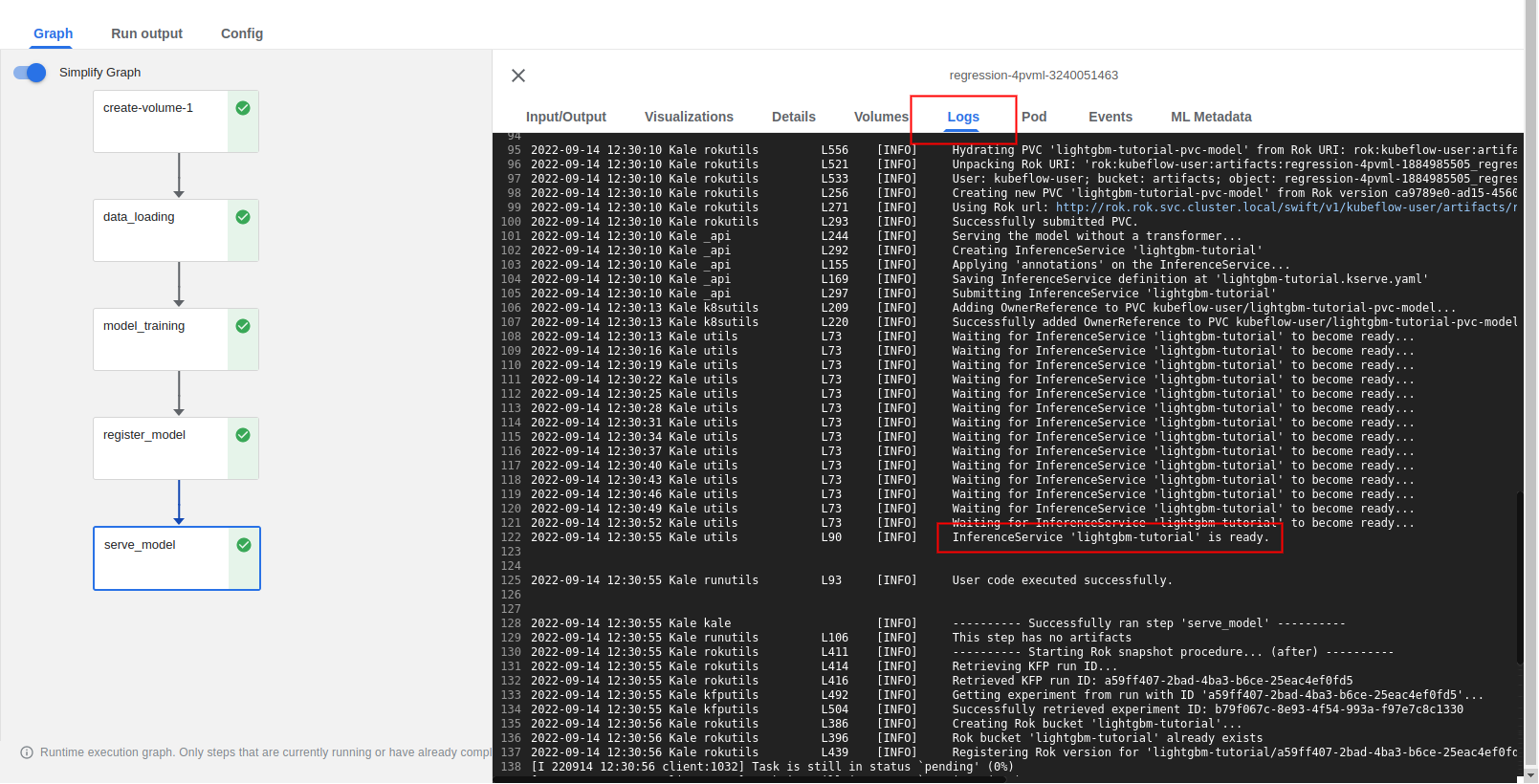
Select Models and click on the endpoint you created:
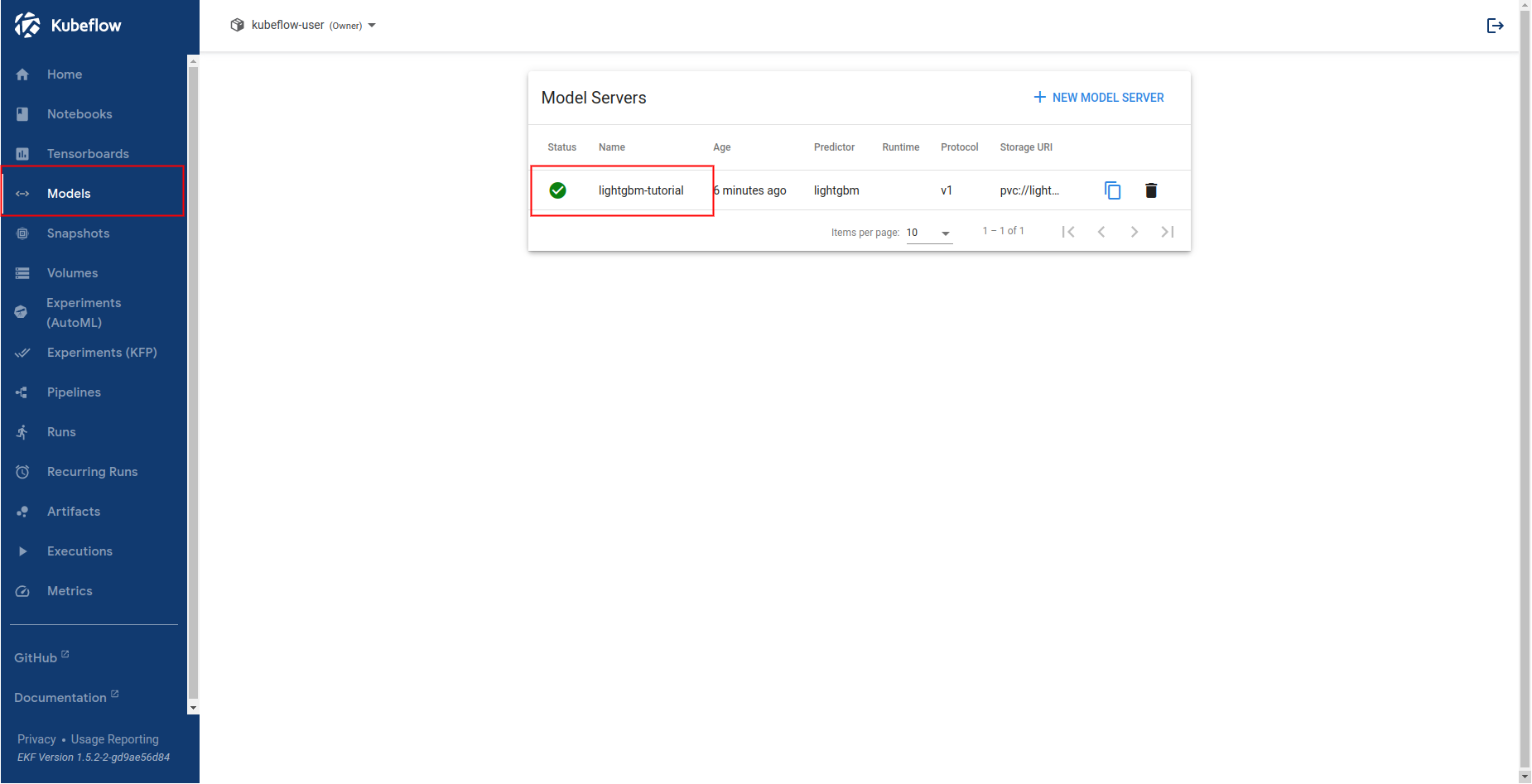
Get Predictions¶
In this section, you will query the model endpoint to get predictions for the examples in the validation subset.
Navigate to the Models UI to retrieve the name of the
InferenceService. In this example, it isxgboost-tutorial.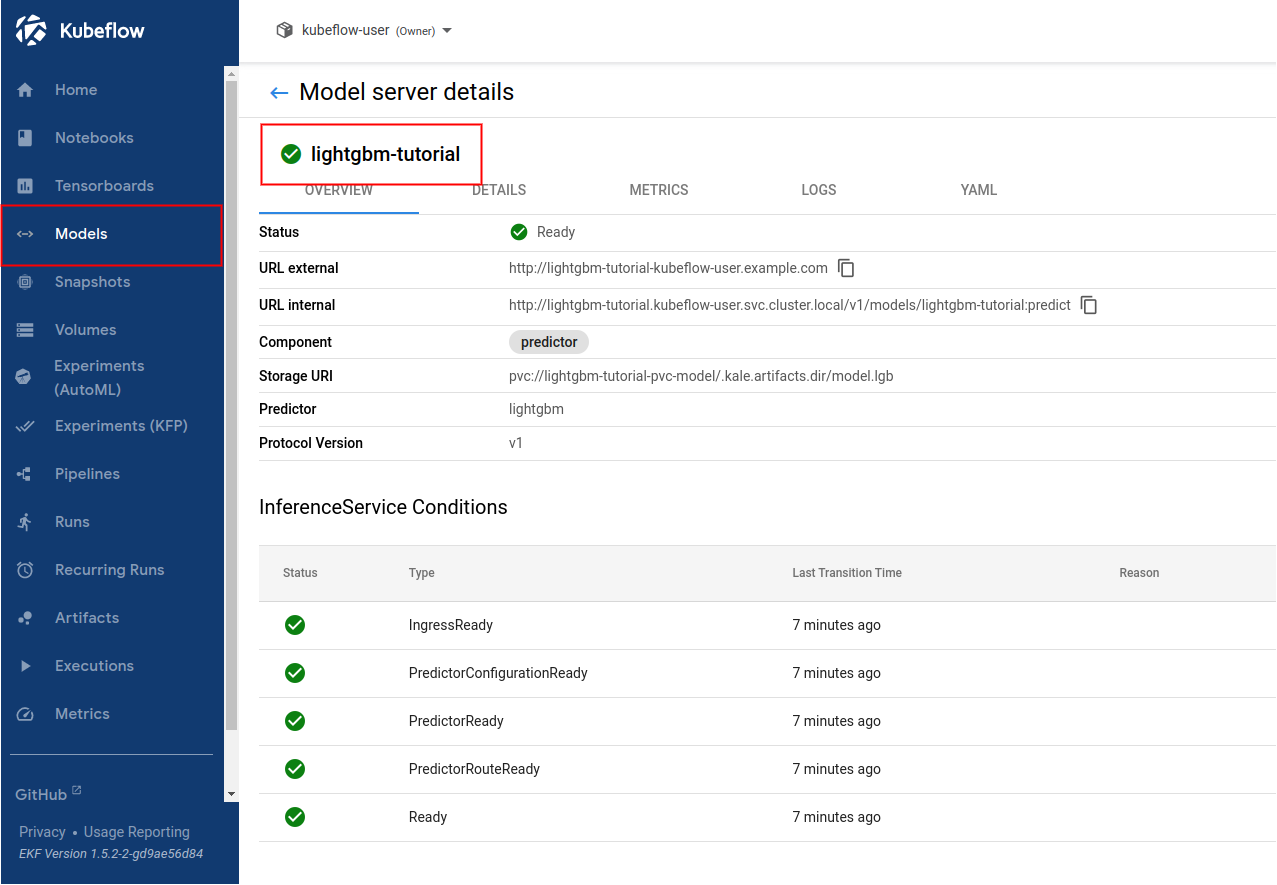
In the existing notebook, in a different code cell, initialize a Kale
Endpointobject using the name of theInferenceServiceyou retrieved in the previous step. Then, run the cell:Note
When initializing an
Endpoint, you can also pass the namespace of theInferenceService. For example, if your namespace ismy-namespace:If you do not provide one, Kale assumes the namespace of the notebook server. In our case is
kubeflow-user.This is how your notebook cell will look like:

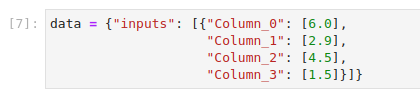
Examine a test sample and convert it into JSON format:
This is how your notebook cell will look like:

Prepare the data payload for the prediction request. Copy and paste the following code in a new cell, and run it:
This is how your notebook cell will look like:
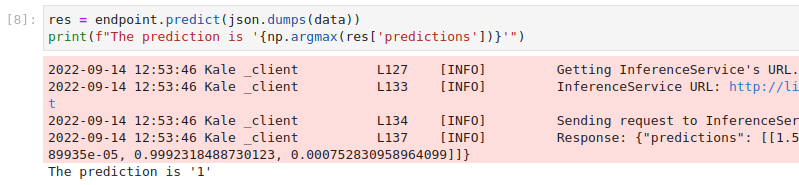
Invoke the server to get predictions. Copy and paste the following snippet in a different code cell, and run it:
This is how your notebook cell will look like:
Summary¶
You have successfully created a Kubeflow pipeline that trains a LightGBM model,
logs it in MLMD, and creates a model endpoint using the Kale serve API.
What’s Next¶
Check out how you can serve a Python function using the Triton Inference Server.