
Serving Integration¶
Attention
This feature is a Tech Preview, so it is not fully supported by Arrikto and may not be functionally complete. While it is not intended for production use, we encourage you to try it out and provide us feedback.
Read our Tech Preview Policy for more information.
The Kale Serve API provides a suite of functions to streamline and simplify serving your Machine Learning (ML) models with KServe. KServe is the EKF component that provides a highly scalable, performant, and standardized inference solution for several ML frameworks on Kubernetes.
To get started with the Kale Serve API, you don’t have to be familiar with KServe. However, once you get past the simple scenarios, you can learn more about the advanced KServe features that let you customize your endpoints and experiment with several deployment strategies, such as:
- Request batching
- Multi-model serving
- Canary deployments
- Model explainability & monitoring
Model Management¶
Kale uses two components to simplify model management: Rok and MLMD. Rok integrates with Kubernetes through the Container Storage Interface (CSI) standard to provide advanced storage capabilities, such as dynamic provisioning of a volume, snapshotting, and topology-aware scheduling of volumes. On the other hand, Machine Learning Metadata (MLMD) is a library for recording and retrieving metadata associated with ML and data science workflows.
Kale uses:
- MLMD to store Model and ML workflow metadata information to enable lineage tracking and model management
- Rok as an artifact store to save trained models and other objects that are necessary for the deployment
Model Artifacts¶
A Kubeflow artifact is an immutable output emitted by a pipeline component, which the Kubeflow Pipelines UI understands. Kale logs these artifacts using MLMD and links them to the current pipeline step and experiment execution.
An artifact is a collection of metadata about an object and a reference to a file or directory containing the actual object. One type of artifact is the model artifact. The model artifact captures information about the model, such as its version, framework, and architecture, as well as a reference to the packaged object. This reference is a URI that points to a specific location in a Rok snapshot or a bucket in an object storage service, like S3.
Kale provides APIs to create Model Artifacts, link it with its context, and serve it with KServe. The following section describes how to use these APIs.
Serve a Model Artifact¶
Let’s see how serving a model with Kale looks like. The following figure depicts the steps of a simple ML pipeline that trains and serves a model.
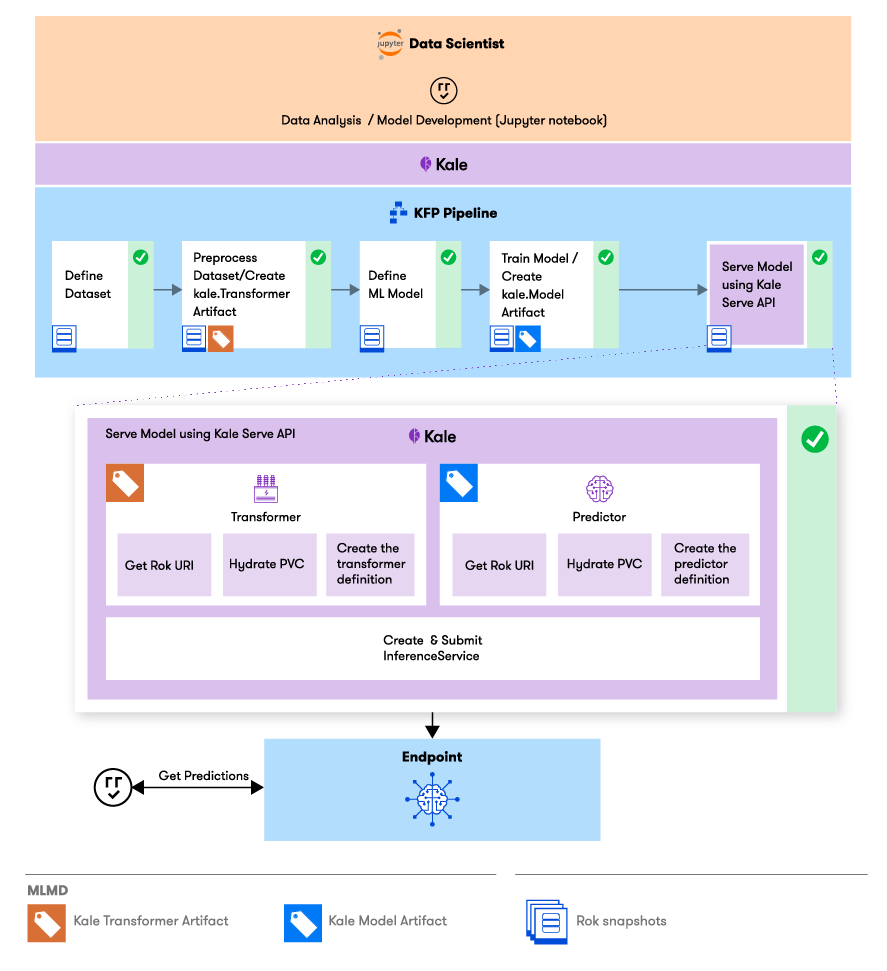
Define the dataset: Explore your dataset and split it into training and test subsets.
Process the dataset: Transform and augment your dataset. During inference you’d want to transform the data in the same way you did during training. To this end, you can create and submit a transformer artifact, that you will use later to deploy a transformer component for your inference service.
transformer_artifact = artifacts.Transformer(name="Vectorizer", transformer_dir="...") transformer_artifact.submit_artifact()Note
You can learn more about creating and logging transformer artifacts by following the Scikit Learn and XGBoost user guides.
Define and train your ML model: Build your model architecture and fit it to the training data. Finally, create a model artifact and log it to MLMD.
model_artifact = Model(model=model, description="My model", version="1.0.0", author="Kale", tags={"stage": "development"}) model_artifact.submit_artifact()Serve the model using the Kale Serve API. Kale will use the Transformer and Model artifacts you submitted to create an KServe
InferenceServicewith a transformer and a predictor component. Specifically, Kale will:- retrieve the Rok URI from the artifact IDs, which points to the location of the model and transformer objects in a Rok snapshot
- hydrate PVCs with the Rok snapshots from these URIs
- create and submit the
InferenceServiceCR, attaching the PVCs to the transformer and predictor pods
from kale.serve import serve isvc = serve(model_artifact_id, transformer_artifact_id)Invoke your model’s endpoint to get predictions in real time:
from kale.serve import Endpoint endpoint = Endpoint(model_server_name) predictions = endpoint.predict(features)Kale will send a POST request to your inference service. The request will be routed to the transformer component, which will transform the data and pass it to the predictor component. The predictor component will return the predictions back to the transformer component, which will postprocess them and return the response to the client.
To learn more about the serving flow, read through the Serving Architecture section and the KServe control plane documentation.
Note
The transformer component is optional. You can choose to deploy only the model as a predictor. In this case, you need to process the data locally, before sending them to the predictor and also handle the response yourself.
Serving Runtimes¶
KServe supports serving several ML frameworks using different runtimes, such as TFServing, Triton, and MLServer. In addition, KServe provides basic API primitives to allow you to build custom model serving runtimes easily.
The following table summarizes the model serving runtimes that KServe provides out-of-the-box. For more information about each runtime, refer to the KServe documentation.
| Runtime | Supported Frameworks | Prediction Protocol | REST | gRPC |
|---|---|---|---|---|
| Triton Inference Server | TensorFlow, PyTorch, ONNX, Python functions | v2 | Yes | Yes |
| TFServing | TensorFlow | v1 | Yes | Yes |
| TorchServe | PyTorch | v1/v2 | Yes | Yes |
| MLServer | Scikit Learn, XGBoost | v2 | Yes | Yes |
| ModelServer | Scikit Learn, XGBoost, PMML, LightGBM, Custom code | v1 | Yes | No |
To learn more about the ServingRuntimes, how to use them and how to create custom ones please refer to the ServingRuntimes documentation.
Note
KServe supports two different prediction protocols: v1 and v2. The v1 protocol is based on the TensorFlow Serving API. The v2 protocol addresses several issues found with the v1 protocol, including performance and generality across a large number of model frameworks and servers. Please refer to the KServe predict protocol documentation for a full specification of the v2 protocol.
Tutorials¶
Follow the tutorials below to experience hands on how to serve models with your favourite ML framework.